START TRANSACTION; INSERT INTO Tab1 ( Num ) VALUES ( 5 ); UPDATE Tab1 SET Num = 6 WHERE Num = 5; DELETE FROM Tab1 WHERE Num = 6; COMMIT;
When a transaction occurs, we want to record statement of that transaction as quickly as possible. 1) We write to files that are called "Write Ahead Log" (WAL). These files are just temporary notes. 2) We write down only essential data. 3) We write sequentially onto disk. That is faster. 4) We buffer these notes in memory and we write them to disk in batches. 5) We do not recalculate indexes of any table.
The WAL usually stores operations, not the final table pages. It doesn't store any data. WAL files are binary files.
UPDATE Products SET Color = 'Red' WHERE ID = 1007
If we are afraid that we will forgot something from our memory, we will write it down. That is the idea behind WAL files.
"The best memory is not as good as a bad pen."
WALs are used when the system becomes corrupted and crash? After we fix the system, we can read from the WAL about: a) Transactions that are complete and are not written to a table. We can write them after the system is repaired, from the WAL notes. This is how we provide durability. These transactions will not be lost. b) Transactions that are incomplete in the WAL will be discarded. We don't want incomplete transactions.
Normal tables
For normal tables, we will create WAL record the fastest we can.
When the database is ready to write to a table, then it will transfer changes from the RAM into database.
After we successfully recorded our transaction, we can delete our WAL file, we don't need it any more.
Unlogged Tables
Unlogged Tables are just like normal database tables, except they are not using WAL. Transaction exists only in RAM memory, until it is written to a table.
Unlogged tables are almost like normal tables: 1) They are written to disk. 2) After normal shutdown of a system, content of unlogged tables will be preserved ( not in MonetDB, but MonetDB is exception ). 3) Content of these tables is available to all of the users, just like for normal tables.
The only difference is in the case of the system crash. After the crash, content of normal tables will be restored to a consistent state by using WAL. Unlogged table will be truncated during the recovery. Server can not guarantee consistency of unlogged tables without WAL, so it will delete their content. This is why unlogged tables should be used only for temporary and re-creatable data.
Writing to unlogged tables can be several times faster then writing to normal tables. Without WAL, we can write much faster, because we are writing only to RAM memory. We are sacrificing reliability of unlogged tables for better write performance.
Unlogged Tables in MonetDB
I will login as administrator. I will change current schema to "voc".
This is how we create unlogged table in MonetDB. CREATE UNLOGGED TABLE UnLogTab ( Number INTEGER ); INSERT INTO UnLogTab ( Number ) VALUES ( 1 ); SELECT * FROM UnLogTab;
If we quit our session, and we log in again, we will still be able to use our unlogged table. quit mclient -u monetdb -d voc SELECT * FROM voc.UnLogTab;
Both the data and the table structure will be preserved. Unlogged table can last through several sessions.
I will create another session as a "voc" user.
mclient -u voc -d voc –password voc
This other session will also be able to read and modify UnLogTab table. UPDATE UnLogTab SET Number = 2; SELECT * FROM UnLogTab;
Sample Table
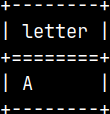
I will create one normal sample table in the "voc" schema, from the admin session: CREATE TABLE voc.Tab1 ( Letter VARCHAR(10) ); INSERT INTO voc.Tab1 VALUES ( 'A' ); SELECT * FROM voc.Tab1;
What Happens After the Crash?
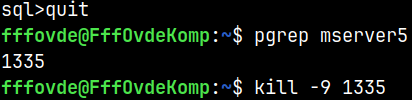
I will exit both sessions from above. We are now in the shell. The number of mserver5 process is 1335. pgrep mserver5 --process 1335 I will kill this process. kill -9 1335
We have now violently closed our server.
I will again start my "voc" database and I will log in as administrator. monetdb start voc mclient -u monetdb -d voc
If we now read from our table, our table will be empty. Because of crash, MonetDB truncated this table.
SELECT * FROM voc.UnLogTab;
But, if we read from the sample table, everything will be fine: SELECT * FROM voc.Tab1;
Difference Between MonetDB and Some Other Servers
I will again add some data to UnLogTab: INSERT INTO voc.UnLogTab ( Number ) VALUES ( 1 ); SELECT * FROM voc.UnLogTab;
This time I will restart my server gracefully. quit monetdb stop voc monetdb start voc mclient -u monetdb -d voc --password monetdb
Our UnLogTab will be empty. This is opposite from some other servers, where regular restart doesn't remove the content of the unlogged tables. In MonetDB, the content will be lost. SELECT * FROM voc.UnLogTab;
--ALTER TABLE Tab1 SET UNLOGGED; --ALTER TABLE UnLogTab SET LOGGED;
Unlike some other databases, MonetDB doesn't have ability to transform unlogged tables to logged tables and vice versa. These statements will not work.
System Tables
We can find information about unlogged tables in the sys.tables and sys.statistics.
SELECT * FROM sys.tables WHERE name = 'unlogtab';
SELECT * FROM sys.statistics WHERE table = 'unlogtab';
In the system table sys.table_types we can see that unlogged tables are of the type 7.
In the warehouse, we don't pack all our goods into one huge box.
Instead, we organize our goods properly into sections, pallets, and boxes. This way, we can easily find, label, and manipulate our inventory.
In databases everything is automated. We don't have to worry about organization ourselves. The problem arises when our table becomes too big. Rebuilding indexes becomes slow, backup/restore is slow, fragmentation of a database is significant.
There is also the fact that in enterprise databases, most of the data is read-only, and only the most recent data is read/written. All this led us to the conclusion that parts of our table should be treated and processed separately. That is why we apply partitioning.
Partitioning is when we divide our table horizontally to several smaller tables.
Benefits and Drawbacks of Partitioning
Queries are faster. Instead of scanning the entire table, we will scan only the necessary partitions. The database is smart enough to discard partitions that do not have a relevant date. This is called "partition pruning". For example, to see sales only for the year 2024, we can query only the 2024 partition and ignore all the others.
Rebuilding indexes, updating statistics, vacuuming is easier for partitions.
Dropping, archiving, backing up, partition swapping, can be done on one part of the table. We can treat the parts of the table separately.
Partitions can be processed in parallel, on different CPU cores. Partitions can be on different storage disks.
Partitions with older/stable data can be compressed and can have multiple indexes. It is the opposite for the most recent data.
Partitioning is only really useful when we have really large tables. Large tables are those with over 100 million rows. The biggest benefit is in maintaining such large tables. It is questionable whether partitioning will improve query speeds. This will only happen if queries exclusively touch some of the partitions and not others. If there is a discrepancy between how users discriminate the data and how we have defined our partitions, we could reduce performance rather than improve it.
Simple Start
First, we will create merge table. It is not possible to query this table until we add some partitions to it.
CREATE MERGE TABLE Merg ( Letter VARCHAR(10), Number INT ); SELECT * FROM Merg;
Now, we will create two sample tables. We will attach these tables as partitions to "Merg" table. Sample tables should have the same exact definitions.
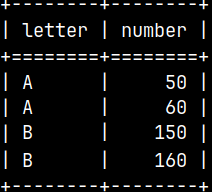
CREATE TABLE Tab1 ( Letter VARCHAR(10), Number INT ); INSERT INTO Tab1 (Letter, Number) VALUES ('A', 50), ('A', 60);
CREATE TABLE Tab2 ( Letter VARCHAR(10), Number INT ); INSERT INTO Tab2 (Letter, Number) VALUES ('B', 150), ('B', 160);
"Tab1" and "Tab2" will be attached to "Merge" table. ALTER TABLE Merg ADD TABLE Tab1; ALTER TABLE Merg ADD TABLE Tab2;
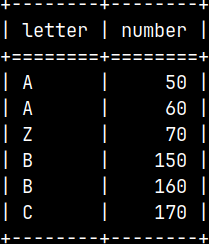
SELECT * FROM Merg;
We can see that merge tables are similar to union queries. UNION queries are verbose, while merge table queries are short and simple. UNION queries are more computationally intensive and use more memory. A merge table can effectively use indexes that are set up over individual partition tables.
On the other hand, UNION queries are necessary when the base tables have different structures that require transformation.
System Tables and Removing Partitions
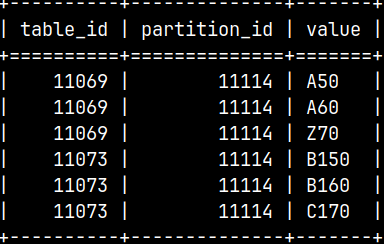
This system table will show us partitions of our merge table. ID of the merge table is 11077.
SELECT * FROM sys.dependencies_vw WHERE used_by_id = 11077;
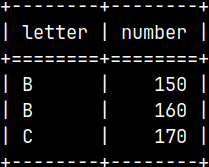
This is how we can remove partition from the Merge table. ALTER TABLE Merg DROP TABLE Tab1; SELECT * FROM Merg;
Merge table now has only one partition, and that is Tab2 partition.
Tab1 is only removed from the merge table. We still have Tab1 in our schema intact.
Problem With Simple Approach
If we try INSERT, UPDATE, DELETE, TRUNCATE on the merge table, we will fail. UPDATE Merg SET Number = 170 WHERE Letter = 'B';
We will delete our merge table, because we want to create it in a way that will allow INSERT, UPDATE, DELETE, TRUNCATE. DROP TABLE Merg;
This time we will provide merge table with a rule by which merge table will differentiate between partitions.
CREATE MERGE TABLE Merg ( Letter VARCHAR(10), Number INT ) PARTITION BY VALUES ON ( Letter );
We now have a system to help merge table to understand distribution of values between partitions. Merge table now knows that partitions are defined based on the values in the "Letter" column.
Next step is to add partitions. Again, we have to use PARTITON clause.
I will try to deceive merge table. I will try to plant table "Tab1" as a table that has the letter 'Z' in the "Letter" column. We know that "Tab1" only has letter "A" in the "Letter" column. ALTER TABLE Merg ADD TABLE Tab1 AS PARTITION IN ( 'Z' ); Merge table will reject this partition.
Only when I truthfully declare my partition as defined by the "A" in the "Letter" column, will my partition be accepted. ALTER TABLE Merg ADD TABLE Tab1 AS PARTITION IN ( 'A' );
But what if I have another table that only has "A" in the "Letter" column. I will create such table, and I will try to add it to the merge table.
CREATE TABLE Tab3 AS ( SELECT * FROM Tab1 ) WITH DATA; ALTER TABLE Merg ADD TABLE Tab3 AS PARTITION IN ( 'A' );
Now we have a conflict. Definitions of partitions have to be unique. "Tab3" will be rejected.
Partition With Multiple Values in the Letter Column
I will add one more row in the "Tab2" table. After that I will add "Tab2" to the merge table.
INSERT INTO Tab2 ( Letter, Number ) VALUES ( 'C', 170 ); SELECT * FROM Tab2; I will declare that my new partition has two letters in the "Letter" column. Merge table will accept this. ALTER TABLE Merg ADD TABLE Tab2 AS PARTITION IN ( 'B', 'C' ); This ability can help us if we don't have uniform distribution of the letters, but we want partitions to be of the same size.
Let's Try Modifying "Merg" Table Directly
Let us now try to INSERT a row directly into "Merg" table.
INSERT INTO Merg ( Letter, Number ) VALUES ( 'Z', 999 ); There is no "Z" partition, so this INSERT will be rejected.
INSERT INTO Merg ( Letter, Number ) VALUES ( 'A', 70 ); Success! "Merg" now knows where to insert a new row (into "Tab1").
Let's update this new row. UPDATE Merg SET Number = 71 WHERE Letter = 'A' AND Number = 70;
Let's delete this new row. DELETE FROM Merg WHERE Letter = 'A' AND Number = 71;
But what if I modify "Tab1" directly. Will that confuse "Merge" table? UPDATE Tab1 SET Letter = 'Z'; <= As we can see, merge table is protected from the rule violation.
Redefining A Partition
We have new records with the letter "Z", but we have only a few of them. I want to add them to "Tab1" partition. We know that "Tab1" will reject them.
In order to avoid that, I will redefine "Tab1" to accept "Z" record. ALTER TABLE Merg SET TABLE Tab1 AS PARTITION IN ( 'A', 'Z' );
Let's insert now "Z" record into "Tab1". INSERT INTO Merg ( Letter, Number ) VALUES ( 'Z', 70 ); "Merg" table will now accept "Z" record.
Other Ways How to Define Partitioning Rule
Partition By Range
This is the current state of table "Tab1" and "Tab2". We can notice that "Tab1" has values in the range "1-100", and "Tab2" has values in the range "101-200". We will use that fact to create new merge table based on these values.
CREATE MERGE TABLE MergRange ( Letter VARCHAR(10), Number INT ) PARTITION BY RANGE ON ( Number );
We'll add "Tab1" and "Tab2" to this new "MergRange". Problem is that one table can not be part of several merge tables.
ALTER TABLE MergRange ADD TABLE Tab1 AS PARTITION FROM 1 TO 100;
We will first remove "Tab1" and "Tab2" from the "Merg" table, and then we will add them to the "MergRange" table.
ALTER TABLE Merg DROP TABLE Tab1; ALTER TABLE Merg DROP TABLE Tab2;
ALTER TABLE MergRange ADD TABLE Tab1 AS PARTITION FROM 1 TO 100; ALTER TABLE MergRange ADD TABLE Tab2 AS PARTITION FROM 101 TO 200;
This would be our new merge table. SELECT * FROM MergRange;
Note, that we would get the same result with these definitions. ALTER TABLE MergRange ADD TABLE Tab1 AS PARTITION FROM RANGE MINVALUE TO 100; ALTER TABLE MergRange ADD TABLE Tab2 AS PARTITION FROM 101 TO RANGE MAXVALUE;
Partition By Value Expression
So far, we have only defined partitions using a single column. Now we will use expression to define partitions. Expression "Letter || CAST( Number AS VARCHAR(10))" says that columns "Number" and "Letter", together, define partition.
CREATE MERGE TABLE MergExpression ( Letter VARCHAR(10), Number INT ) PARTITION BY VALUES USING ( Letter || CAST( Number AS VARCHAR(10) ));
We will remove "Tab1" and "Tab2" from the merge table "MergRange". Then, we will add them to the "MergExpression" table.
ALTER TABLE MergRange DROP TABLE Tab1; ALTER TABLE MergRange DROP TABLE Tab2;
ALTER TABLE MergExpression ADD TABLE Tab1 AS PARTITION IN ( 'A50', 'A60', 'Z70' ); ALTER TABLE MergExpression ADD TABLE Tab2 AS PARTITION IN ( 'B150', 'B160', 'C170' );
We get the same result again.
SELECT * FROM MergExpression;
Partition by Range Expression
It is also possible to use an expression to calculate the value that will be used to determine range membership.
CREATE MERGE TABLE MergRangeExpression ( Letter VARCHAR(10), Number INT ) PARTITION BY RANGE USING ( Number + char_length( Letter ) );
Again, we will untie our tables from the previous merge table, and then we will add them to the MergRangeExpression table.
ALTER TABLE MergExpression DROP TABLE Tab1; ALTER TABLE MergExpression DROP TABLE Tab2;
ALTER TABLE MergRangeExpression ADD TABLE Tab1 AS PARTITION FROM 1 TO 100; ALTER TABLE MergRangeExpression ADD TABLE Tab2 AS PARTITION FROM 101 TO 200;
Partition By NULLS
We have to declare what partition will have nulls. Obviously we have to place all the NULLS into only one partition.
ALTER TABLE Merg ADD TABLE Tab1 AS PARTITION IN ( 'A' ) WITH NULL VALUES;
In this case all nulls would belong to partition "Tab1".
ALTER TABLE Merg ADD TABLE Tab2 AS PARTITION FROM 1 TO 9 WITH NULL VALUES;
All nulls belong to partition "Tab2".
ALTER TABLE Merg ADD TABLE Tab3 AS PARTITION FOR NULL VALUES;
In this case, all nulls belong to partition "Tab3".
PARTITION System Tables
When we define partitioning rule (when we use PARTITION clause), that partition rule will be register in these system tables.
Here we can find our three merge tables. Two of them are using individual columns, and the third one is using an expression. SELECT * FROM sys.table_partitions;
Here we can find values used to determine partitions.
SELECT * FROM sys.value_partitions;
System table "sys.range_partitions" is used when partitioning is made by the ranges ( 1-100, 101-200 ).
Merge Table Based on Another Table
It is possible to give merge table definition from some other table. WITH NO DATA is mandatory. CREATE MERGE TABLE MergAS ( Letter, Number ) AS ( SELECT * FROM Tab1 ) WITH NO DATA;
We will login as adminstrators, but we will set VOC shema as current. Password is "monetdb".
mclient -u monetdb -d voc; SET SCHEMA voc;
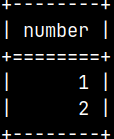
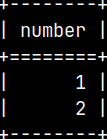
CREATE TABLE permTable ( Number INTEGER ); INSERT INTO permTable ( Number ) VALUES ( 1 ), ( 2 );
Temporary Tables
After the execution of the query, if the result is not saved in a table or sent to an application, the result of a query will be discarded. Queries are transient, but tables are permanent. Tables will permanently save data stored in them. Between queries and tables, we have temporary data structures called temporary tables. These structures are used to store session-specific data that only needs to exist for a short duration.
Creation of a Local Temporary Table
We will create a temporary table that will exist only during one session. Such temporary tables are called LOCAL temporary tables.Default behavior of temporary tables is to lose their content at the end of transaction. We can prevent that with option on commit PRESERVE ROWS. We don't want the temporary table to be emptied at the end of the transaction because we want to observe the behavior of the table.
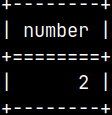
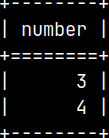
CREATE LOCAL TEMPORARY TABLE tempTable ( Number INTEGER PRIMARY KEY ) ON COMMIT PRESERVE ROWS; INSERT INTO tempTable ( Number ) VALUES ( 3 ), ( 4 ); SELECT * FROM tempTable;
Temporary tables are created in "tmp" schema. We don't have to prefix their names with "tmp". Both statements bellow will work the same SELECT * FROM tempTable; SELECT * FROM tmp.tempTable;
We can not create temporary table in some schema other than "tmp". CREATE LOCAL TEMPORARY TABLE voc.tempTable2 ( Number INTEGER PRIMARY KEY );
Permanent table and temporary table can have the same name because they are in different schemas. I will create one temporary table with the name "permTable". CREATE LOCAL TEMPORARY TABLE permTable ( Number INTEGER ); If we read from the "permTable" without specifying schema, we will get the temporary table. SELECT * FROM permTable; For reading from the permanent table with the same name, we have to use fully qualified name. SELECT * FROM voc.permTable; So, temporary table has priority, although our current schema is "voc" (and not "tmp").
We can not create permanent objects in "tmp". SET SCHEMA tmp; CREATE TABLE ZZZ ( Number INTEGER ); SET SCHEMA voc;
Usage of a Temporary Table
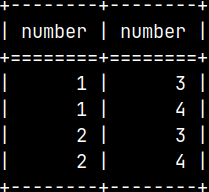
It is possible to create queries that combine temporary and normal tables. SELECT * FROM voc.permTable JOIN tempTable ON permTable.Number <= tempTable.Number;
We can have constraints on the temporary table. In this case we have PK constraint. INSERT INTO tempTable ( Number ) VALUES ( 3 );
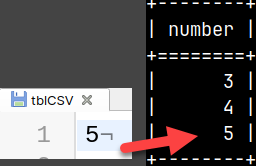
It is possible to export data from temporary table into CSV. COPY SELECT * FROM tempTable INTO '/home/fffovde/Desktop/tblCSV';
It is possible to import data from a CSV file into temporary table. COPY INTO tempTable ( Number ) FROM '/home/fffovde/Desktop/tblCSV'( Number );
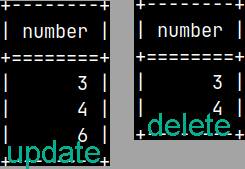
It is possible to use UPDATE and DELETE on temporary tables.
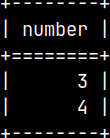
UPDATE tempTable SET Number = 6 WHERE Number = 5; DELETE FROM tempTable WHERE Number = 6;
We can NOT alter our temporary table. ALTER TABLE tempTable ADD COLUMN Letter VARCHAR(10);
ALTER TABLE tempTable DROP CONSTRAINT temptable_number_pk;
It is possible to create a view on a temporary table. CREATE VIEW voc.View1 ( Number ) AS SELECT * FROM tmp.tempTable; SELECT * FROM View1;
It is not possible to create foreign key constraint on the permTable if it references tempTable. ALTER TABLE voc.permTable ADD CONSTRAINT FromTempTableConstraint FOREIGN KEY ( Number ) REFERENCES tmp.tempTable ( Number );
Info About Temporary Tables
We can NOT get statistics about our temporary table. SELECT * FROM sys.statistics( 'tmp','temptable');
We can find our temporary table in the system catalog. SELECT * FROM sys.tables WHERE Name = 'temptable';
Visibility of Local Temporary Table
I will log in to MonetDB from another instance of mclient, as "voc" user (password "voc"). mclient -u voc -d voc I will try to read local table "tempTable". SELECT * FROM tempTable; This will not work, because local temporary table are visible only in the session where they are created. Other users can not see these tables.
As the user "voc" I will create temporary table with the same name -"tempTable". This will be successful. Each user can have its own local temp table. CREATE LOCAL TEMPORARY TABLE tempTable ( Number INTEGER );
Even if we don't explicitly drop the table, our table will disappear after we log out of the current session. I'll log out of the session ( monetdb user session ), and after I log back in, "tempTable" will no longer exist. quit mclient -u monetdb -d voc SELECT * FROM tempTable;
We can terminate our "tempTable" by dropping it explicitly, even before the end of the session.
DROP TABLE tempTable;
ON COMMIT DELETE ROWS
"ON COMMIT DELETE ROWS" subclause means that after each transaction, data will be deleted. This is default behavior.
CREATE LOCAL TEMPORARY TABLE tempTable ( Number INTEGER PRIMARY KEY ) ON COMMIT DELETE ROWS; INSERT INTO tempTable ( Number ) VALUES ( 3 ), ( 4 ); SELECT * FROM tempTable;
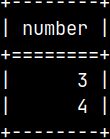
In this case, temporary table is useful only inside of transaction. START TRANSACTION; INSERT INTO tempTable ( Number ) VALUES ( 3 ), ( 4 ); SELECT * FROM tempTable;
COMMIT;
AS SELECT
We can create temporary table based on some other table. Base table can be temporary or normal table.
CREATE LOCAL TEMPORARY TABLE tempTable2 ( Number ) AS ( SELECT Number FROM tempTable );
CREATE LOCAL TEMPORARY TABLE tempTable3 ( Number ) AS (SELECT Number FROM voc.permTable ) ON COMMIT PRESERVE ROWS;
By defult we will use "WITH DATA". If try to read from tempTable3, we'll see the values. SELECT * FROM tempTable3;
The "WITH NO DATA" subclause will make us not to inherit data. CREATE LOCAL TEMPORARY TABLE tempTable4 ( Number ) AS ( SELECT Number FROM voc.permTable ) WITH NO DATA ON COMMIT PRESERVE ROWS; SELECT * FROM tempTable4;
Global Temporary Tables
Global temporary tables are somewhere between normal tables and local tables. Their definition ( columns and data types ) is permanent. Name of the global table has to be unique in the "tmp" schema. Only users with authorization over "tmp" schema can create global temporary tables. In our example, administrator "monetdb" can create global temporary tables, but "voc" user can not.
The thing that makes these tables temporary is their data. All the rows of the global temporary tables will be deleted after each transaction (for ON COMMIT DELETE ROWS) or after the session (ON COMMIT PRESERVE ROWS).
While definition of the global temporary tables is shared, data is not. Data placed in the global table by one user can not be seen by another user. So, global temporary table is a playground where each user can play with his own data.
Global temporary tables have similar characteristics as local temporary tables. We can use SELECT, DELETE, UPDATE. We can export them to CSV file. We can NOT alter global tables. We can create views on them. So, everything is the same as for local temporary tables.
It is possible to get statistics about global tables. SELECT * FROM sys.statistics( 'tmp','globtable');
Creation of the Global Temporary Table
We create global temporary table with similar statement as for the local temporary tables.
CREATE GLOBAL TEMPORARY TABLE globTable ( Number INTEGER PRIMARY KEY ) ON COMMIT PRESERVE ROWS;
This will fail for the "voc" user who doesn't have enough privileges over "tmp" schema.
Privileged users can successfully create global temporary table, but not if the table with such name already exist. It is not possible for two users to create global tables with the same names.
Visibility of Global Temporary Table
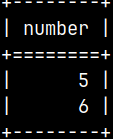
We will insert some data in our global temporary table. INSERT INTO globTable ( Number ) VALUES ( 5 ), ( 6 ); SELECT * FROM globTable;
If we try to read our table from the session of the "voc" user, we will see empty table. This show us that definition of a table is shared, but data is not shared. SELECT * FROM globTable;
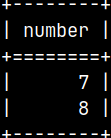
Although "voc" user can not create global table, it can use tables created by others. "Voc" user can play with his own data. INSERT INTO globTable ( Number ) VALUES ( 7 ), ( 8 ); SELECT * FROM globTable;
When to Use Temporary Tables
You can create an excerpt from some big table. After that, you can run you queries on that smaller table, instead of the big one.
Because temporary tables are volatile and data is isolated between users, so temporary tables are great for experiments.
Temporary tables should not be used as an intermediate step in queries. In that case, it is much wiser to use CTE.
Loader functions are UDFs (user defined functions), that are used to insert data from various data sources. Currently, we can only make these functions with python programming language.
Idea is, to be able to read from the different data sources by using the power of python.
Monetdb-Python3 Integration Package
Previously, we have installed MonetDB with two packages. We have installed monetdb5-sql and monetdb-client.
For python, we will need one more package. Monetdb-Python3 is integration package that allows MonetDB to interact with python.
sudo apt install monetdb5-sql monetdb-client
sudo apt install monetdb-python3
Command, sudo apt -a list monetdb-python3, will show us that we have 8 different versions of this package in the repository.
Command sudo apt -a show monetdb-python3, will claim that for MonetDB version 11.51.7, we should install version 11.51.7 of monetdb-python3. We should always match versions if we can.
I have the version 11.51.7 of MonetDB server. monetdb --version
I can install the last version of monetdb-python3: sudo apt install monetdb-python3
Or, I can install specific version of monetdb-python3: sudo apt install monetdb-python3=11.51.7
Enabling Embedded Python
I will first start monetdb daemon:
monetdbd start /home/fffovde/DBfarm1
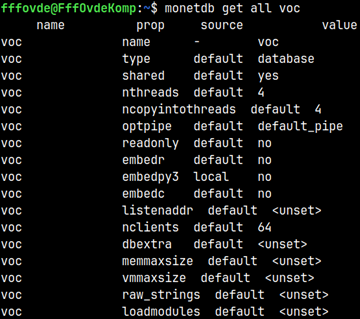
We have to enable python integration package for each database. By typing monetdb get all voc, we can list properties of the voc database.
We can see that for "embedpy3" setting is NO. We will change that. name prop source value voc name - voc voc type default database voc shared default yes voc nthreads default 4 voc ncopyintothreads default 4 voc optpipe default default_pipe voc readonly default no voc embedr default no voc embedpy3 local no voc embedc default no voc listenaddr default<unset> voc nclients default 64 voc dbextra default<unset> voc memmaxsize default<unset> voc vmmaxsize default<unset> voc raw_strings default<unset> voc loadmodules default <unset>
We will stop the database if it is running. Then we will change the setting, and after that we will run our database again. monetdb stop voc monetdb set embedpy3=true monetdb start voc We have changed embedpy3 property to yes.
Now we can login to our database. I will login as an administrator, although that is not needed, any user has ability to create LOADER function.
This statement will create LOADER function. Columns are defined as python lists. Each list, together with the name of a column, is placed inside of the python dictionary.
We are using function "_emit.emit" do divide our inserts into chunks. In this way we can preserve memory. After inserting the first chunk, (A1,B2), we can delete it from the memory, and we can continue inserting the second chunk (C3,D4).
Instead of the python lists, we can also use NumPy arrays. Instead of [1, 2, 3, 4, 5], we can use np.array( [1, 2, 3, 4, 5] ). NumPy arrays are faster.
LOADER functions are of the type 7, so we can read them as "SELECT * FROM sys.functions WHERE type = 7;". We can also notice that our function belongs to schema 2000 (schema sys), because that is the default schema for administrators (I am logged in as an administrator). Creation of LOADER functions is not limited to administrators, every user can create LOADER function.
Using LOADER Function
We can create a table from our LOADER function. Columns and data types will be deduced automatically. CREATE TABLE myLoaderTable FROM LOADER myloader(); SELECT * FROM myLoaderTable;
It is also possible to add data to an existing table. I will first truncate myLoaderTable and then I will append new data to an existing table. TRUNCATE myLoaderTable; COPY LOADER INTO myLoaderTable FROM myloader();
Using a Parameter in a LOADER function
With python we can pull data from anywhere, from any database or file. Here is an example where we will read data from a JSON file.
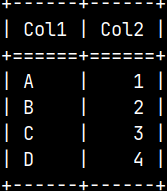
{ "Col1": ["A","B","C","D"] , "Col2": [1,2,3,4] }
We have a JSON file, with the name "File.json".
CREATE LOADER json_loader(filenameSTRING) LANGUAGE PYTHON { import json f = open(filename) _emit.emit(json.load(f)) f.close() };
This is how we can create LOADER function, that will read from our JSON file. This time we are using an argument for our function. This argument is of the STRING data type. STRING is an alias for the CLOB data type in MonetDB.
json module is builtin Python3 module.
We can truncate previous results and we can import from the json file.
TRUNCATE myLoaderTable;
COPY LOADER INTO myLoaderTable FROM json_loader('/home/fffovde/Desktop/File.json'); SELECT * FROM myLoaderTable;
Missing Columns
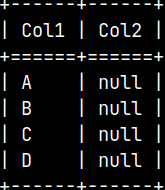
TRUNCATE myLoaderTable;
During the import missing columns will be filled with nulls. CREATE LOADER myloader2() LANGUAGE PYTHON { _emit.emit( { 'Col1': [ "A", "B", "C", "D" ] } ) }; COPY LOADER INTO myLoaderTable FROM myloader2(); SELECT * FROM myLoaderTable;
Delete LOADER function
DROP LOADER FUNCTION sys.myloader2;
We can always delete this function with DROP LOADER FUNCTION statement.
We saw how to import data from CSV file. For exporting to CSV file, we will again use COPY INTO statement.
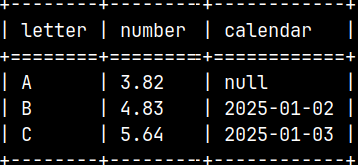
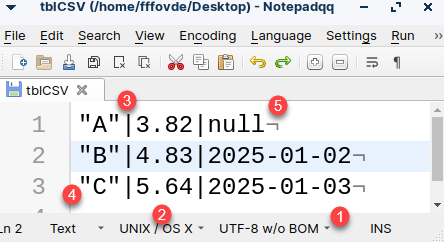
COPY SELECT * FROM tblCSV INTO '/home/fffovde/Desktop/tblCSV';
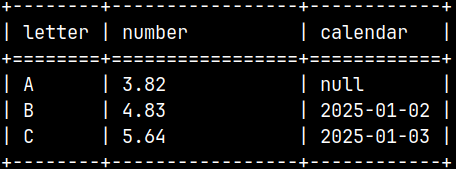
By default, we'll get textual file, in UTF-8 encoding (1). Line endings are going to be LF (2). Column separators are pipes (3). Default string wrappers will be double quotes (4). Nulls will be represented as a >null< (5). Notice that I have omitted "ON SERVER" subclause. Subclause "ON SERVER" is the default.
Default string wrappers are not the same when writing and reading strings. They are double quotes when writing, and empty strings when reading.
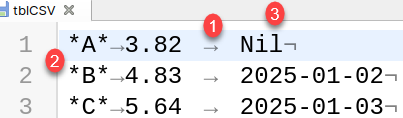
We can change default settings, like in this example. Column separator is TAB sign (1). String wrapper is a star (2). NULLs are represented with >Nil< (3). COPY SELECT * FROM tblCSV INTO '/home/fffovde/Desktop/tblCSV' ON SERVER USING DELIMITERS E'\t', E'\n', '*' NULL AS 'Nil';
We can not overwrite the existing file with the same name. That would return the error.
Exporting Compressed CSV File
If our file name has extensions .xz .bz2 .gz .lz4, then the result file will be compressed. Compression level is the best when using .xz ( .xz > .bz2 > .gz > .lz4 ). For better compression, the more time is needed.
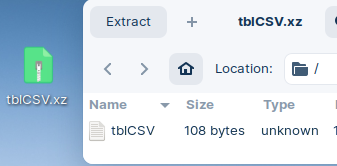
Let's use extreme zip compression (.xz). COPY SELECT * FROM tblCSV INTO '/home/fffovde/Desktop/tblCSV.xz';
Our file is reduced from 648 to 108 bytes.
Exporting CSV File on the Client
I will demonstrate exporting of a CSV file, on the client, by using python. We will use the code bellow. This is the same code used for uploading files, with two distinctions. Instead "set_uploader" we are using "set_downloader". COPY INTO statement is also different.
cursor = connection.cursor() cursor.execute("COPY SELECT * FROM tblCSV INTO '/home/fffovde/Desktop/tblCSV.bz2' ON CLIENT;") connection.commit()
cursor.close() connection.close()
Our file will be saved in compressed state:
Binary Files
MonetDB can import/export data even faster than from/to CSV files. For that we can use binary files.
Little Endian vs Big Endian
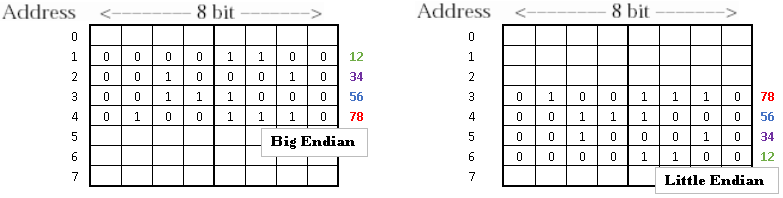
Let's say that we have hexadecimal number 0x12345678. Every two figures represent one byte:
12 => 00001100
34 => 00100010
56 => 00111000
78 => 01001110
When we write our number to memory, we can write it in two ways. – We can write it in order 12345678. This is called Big Endian. – We can write it in the reverse order 78563412. This is called Little Endian.
This distinction is important when writing binary files.
There is also a term Native Endian. That is the preferred byte order of the system MonetDB is running on. If your system is using AMD, ARM, or Intel CPU, then your system is using Little Endian.
We can check the Endianness of our system. lscpu | grep "Byte Order"
Exporting Binary Files
MonetDB can export data into MonetDB custom binary files. Each table column will become a separate file.
COPY SELECT * FROM tblCSV INTO LITTLE ENDIAN BINARY '/home/fffovde/Desktop/Letter', '/home/fffovde/Desktop/Number', '/home/fffovde/Desktop/Calendar' ON SERVER;
As a result, we'll get three binary files. One file for each column.
Instead of "Little Endian" we can use "Big Endian" or "Native Endian". Instead of "ON SERVER", we can use "ON CLIENT". For exporting data on the client, we can reuse the same python script shown above.
Loading Binary Files to MonetDB
Exported binary files can be imported in any MonetDB database. Before import, we can empty database table "TRUNCATE tblCSV;".
COPY LITTLE ENDIAN BINARY INTO tblCSV( Letter, Number, Calendar ) FROM '/home/fffovde/Desktop/Letter', '/home/fffovde/Desktop/Number', '/home/fffovde/Desktop/Calendar' ON SERVER;
TRUNCATE tblCSV;
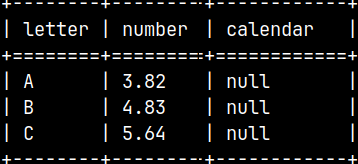
It is possible to load less then three columns. We can see that "Calendar" column is empty. COPY LITTLE ENDIAN BINARY INTO tblCSV( Letter, Number ) FROM '/home/fffovde/Desktop/Letter', '/home/fffovde/Desktop/Number' ON SERVER;
TRUNCATE tblCSV;
COPY LITTLE ENDIAN BINARY INTO tblCSV FROM '/home/fffovde/Desktop/Letter', '/home/fffovde/Desktop/Number', '/home/fffovde/Desktop/Calendar' ON SERVER;
We don't have to declare columns of the database table. In that case, we just have to make sure that order and number of files is the same as the order and number of the columns in the table.
cursor = connection.cursor() cursor.execute("COPY LITTLE ENDIAN BINARY INTO tblCSV FROM '/home/fffovde/Desktop/Letter', '/home/fffovde/Desktop/Number', '/home/fffovde/Desktop/Calendar' ON CLIENT;") connection.commit()
cursor.close() connection.close()
For uploading binary files to MonetDB, from the client, we are using the similar python script that we have used for CSV files.







































 We have a JSON file, with the name "
We have a JSON file, with the name "