In the warehouse, we don't pack all our goods into one huge box.
Instead, we organize our goods properly into sections, pallets, and boxes. This way, we can easily find, label, and manipulate our inventory.
In databases everything is automated. We don't have to worry about organization ourselves. The problem arises when our table becomes too big. Rebuilding indexes becomes slow, backup/restore is slow, fragmentation of a database is significant.
There is also the fact that in enterprise databases, most of the data is read-only, and only the most recent data is read/written. All this led us to the conclusion that parts of our table should be treated and processed separately. That is why we apply partitioning.
Partitioning is when we divide our table horizontally to several smaller tables.
Benefits and Drawbacks of Partitioning
Queries are faster. Instead of scanning the entire table, we will scan only the necessary partitions. The database is smart enough to discard partitions that do not have a relevant date. This is called "partition pruning". For example, to see sales only for the year 2024, we can query only the 2024 partition and ignore all the others.
Rebuilding indexes, updating statistics, vacuuming is easier for partitions.
Dropping, archiving, backing up, partition swapping, can be done on one part of the table. We can treat the parts of the table separately.
Partitions can be processed in parallel, on different CPU cores. Partitions can be on different storage disks.
Partitions with older/stable data can be compressed and can have multiple indexes. It is the opposite for the most recent data.
Partitioning is only really useful when we have really large tables. Large tables are those with over 100 million rows. The biggest benefit is in maintaining such large tables. It is questionable whether partitioning will improve query speeds. This will only happen if queries exclusively touch some of the partitions and not others. If there is a discrepancy between how users discriminate the data and how we have defined our partitions, we could reduce performance rather than improve it.
Simple Start
First, we will create merge table. It is not possible to query this table until we add some partitions to it.
CREATE MERGE TABLE Merg ( Letter VARCHAR(10), Number INT ); SELECT * FROM Merg;
Now, we will create two sample tables. We will attach these tables as partitions to "Merg" table. Sample tables should have the same exact definitions.
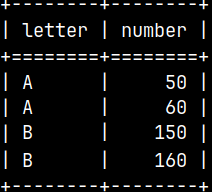
CREATE TABLE Tab1 ( Letter VARCHAR(10), Number INT ); INSERT INTO Tab1 (Letter, Number) VALUES ('A', 50), ('A', 60);
CREATE TABLE Tab2 ( Letter VARCHAR(10), Number INT ); INSERT INTO Tab2 (Letter, Number) VALUES ('B', 150), ('B', 160);
"Tab1" and "Tab2" will be attached to "Merge" table. ALTER TABLE Merg ADD TABLE Tab1; ALTER TABLE Merg ADD TABLE Tab2;
SELECT * FROM Merg;
We can see that merge tables are similar to union queries. UNION queries are verbose, while merge table queries are short and simple. UNION queries are more computationally intensive and use more memory. A merge table can effectively use indexes that are set up over individual partition tables.
On the other hand, UNION queries are necessary when the base tables have different structures that require transformation.
System Tables and Removing Partitions
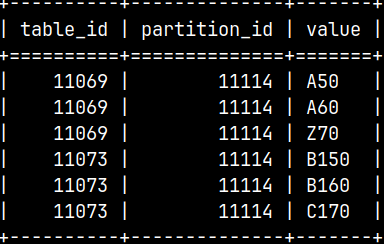
This system table will show us partitions of our merge table. ID of the merge table is 11077.
SELECT * FROM sys.dependencies_vw WHERE used_by_id = 11077;
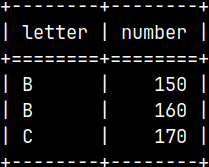
This is how we can remove partition from the Merge table. ALTER TABLE Merg DROP TABLE Tab1; SELECT * FROM Merg;
Merge table now has only one partition, and that is Tab2 partition.
Tab1 is only removed from the merge table. We still have Tab1 in our schema intact.
Problem With Simple Approach
If we try INSERT, UPDATE, DELETE, TRUNCATE on the merge table, we will fail. UPDATE Merg SET Number = 170 WHERE Letter = 'B';
We will delete our merge table, because we want to create it in a way that will allow INSERT, UPDATE, DELETE, TRUNCATE. DROP TABLE Merg;
This time we will provide merge table with a rule by which merge table will differentiate between partitions.
CREATE MERGE TABLE Merg ( Letter VARCHAR(10), Number INT ) PARTITION BY VALUES ON ( Letter );
We now have a system to help merge table to understand distribution of values between partitions. Merge table now knows that partitions are defined based on the values in the "Letter" column.
Next step is to add partitions. Again, we have to use PARTITON clause.
I will try to deceive merge table. I will try to plant table "Tab1" as a table that has the letter 'Z' in the "Letter" column. We know that "Tab1" only has letter "A" in the "Letter" column. ALTER TABLE Merg ADD TABLE Tab1 AS PARTITION IN ( 'Z' ); Merge table will reject this partition.
Only when I truthfully declare my partition as defined by the "A" in the "Letter" column, will my partition be accepted. ALTER TABLE Merg ADD TABLE Tab1 AS PARTITION IN ( 'A' );
But what if I have another table that only has "A" in the "Letter" column. I will create such table, and I will try to add it to the merge table.
CREATE TABLE Tab3 AS ( SELECT * FROM Tab1 ) WITH DATA; ALTER TABLE Merg ADD TABLE Tab3 AS PARTITION IN ( 'A' );
Now we have a conflict. Definitions of partitions have to be unique. "Tab3" will be rejected.
Partition With Multiple Values in the Letter Column
I will add one more row in the "Tab2" table. After that I will add "Tab2" to the merge table.
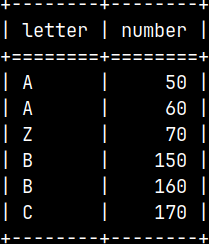
INSERT INTO Tab2 ( Letter, Number ) VALUES ( 'C', 170 ); SELECT * FROM Tab2; I will declare that my new partition has two letters in the "Letter" column. Merge table will accept this. ALTER TABLE Merg ADD TABLE Tab2 AS PARTITION IN ( 'B', 'C' ); This ability can help us if we don't have uniform distribution of the letters, but we want partitions to be of the same size.
Let's Try Modifying "Merg" Table Directly
Let us now try to INSERT a row directly into "Merg" table.
INSERT INTO Merg ( Letter, Number ) VALUES ( 'Z', 999 ); There is no "Z" partition, so this INSERT will be rejected.
INSERT INTO Merg ( Letter, Number ) VALUES ( 'A', 70 ); Success! "Merg" now knows where to insert a new row (into "Tab1").
Let's update this new row. UPDATE Merg SET Number = 71 WHERE Letter = 'A' AND Number = 70;
Let's delete this new row. DELETE FROM Merg WHERE Letter = 'A' AND Number = 71;
But what if I modify "Tab1" directly. Will that confuse "Merge" table? UPDATE Tab1 SET Letter = 'Z'; <= As we can see, merge table is protected from the rule violation.
Redefining A Partition
We have new records with the letter "Z", but we have only a few of them. I want to add them to "Tab1" partition. We know that "Tab1" will reject them.
In order to avoid that, I will redefine "Tab1" to accept "Z" record. ALTER TABLE Merg SET TABLE Tab1 AS PARTITION IN ( 'A', 'Z' );
Let's insert now "Z" record into "Tab1". INSERT INTO Merg ( Letter, Number ) VALUES ( 'Z', 70 ); "Merg" table will now accept "Z" record.
Other Ways How to Define Partitioning Rule
Partition By Range
This is the current state of table "Tab1" and "Tab2". We can notice that "Tab1" has values in the range "1-100", and "Tab2" has values in the range "101-200". We will use that fact to create new merge table based on these values.
CREATE MERGE TABLE MergRange ( Letter VARCHAR(10), Number INT ) PARTITION BY RANGE ON ( Number );
We'll add "Tab1" and "Tab2" to this new "MergRange". Problem is that one table can not be part of several merge tables.
ALTER TABLE MergRange ADD TABLE Tab1 AS PARTITION FROM 1 TO 100;
We will first remove "Tab1" and "Tab2" from the "Merg" table, and then we will add them to the "MergRange" table.
ALTER TABLE Merg DROP TABLE Tab1; ALTER TABLE Merg DROP TABLE Tab2;
ALTER TABLE MergRange ADD TABLE Tab1 AS PARTITION FROM 1 TO 100; ALTER TABLE MergRange ADD TABLE Tab2 AS PARTITION FROM 101 TO 200;
This would be our new merge table. SELECT * FROM MergRange;
Note, that we would get the same result with these definitions. ALTER TABLE MergRange ADD TABLE Tab1 AS PARTITION FROM RANGE MINVALUE TO 100; ALTER TABLE MergRange ADD TABLE Tab2 AS PARTITION FROM 101 TO RANGE MAXVALUE;
Partition By Value Expression
So far, we have only defined partitions using a single column. Now we will use expression to define partitions. Expression "Letter || CAST( Number AS VARCHAR(10))" says that columns "Number" and "Letter", together, define partition.
CREATE MERGE TABLE MergExpression ( Letter VARCHAR(10), Number INT ) PARTITION BY VALUES USING ( Letter || CAST( Number AS VARCHAR(10) ));
We will remove "Tab1" and "Tab2" from the merge table "MergRange". Then, we will add them to the "MergExpression" table.
ALTER TABLE MergRange DROP TABLE Tab1; ALTER TABLE MergRange DROP TABLE Tab2;
ALTER TABLE MergExpression ADD TABLE Tab1 AS PARTITION IN ( 'A50', 'A60', 'Z70' ); ALTER TABLE MergExpression ADD TABLE Tab2 AS PARTITION IN ( 'B150', 'B160', 'C170' );
We get the same result again.
SELECT * FROM MergExpression;
Partition by Range Expression
It is also possible to use an expression to calculate the value that will be used to determine range membership.
CREATE MERGE TABLE MergRangeExpression ( Letter VARCHAR(10), Number INT ) PARTITION BY RANGE USING ( Number + char_length( Letter ) );
Again, we will untie our tables from the previous merge table, and then we will add them to the MergRangeExpression table.
ALTER TABLE MergExpression DROP TABLE Tab1; ALTER TABLE MergExpression DROP TABLE Tab2;
ALTER TABLE MergRangeExpression ADD TABLE Tab1 AS PARTITION FROM 1 TO 100; ALTER TABLE MergRangeExpression ADD TABLE Tab2 AS PARTITION FROM 101 TO 200;
Partition By NULLS
We have to declare what partition will have nulls. Obviously we have to place all the NULLS into only one partition.
ALTER TABLE Merg ADD TABLE Tab1 AS PARTITION IN ( 'A' ) WITH NULL VALUES;
In this case all nulls would belong to partition "Tab1".
ALTER TABLE Merg ADD TABLE Tab2 AS PARTITION FROM 1 TO 9 WITH NULL VALUES;
All nulls belong to partition "Tab2".
ALTER TABLE Merg ADD TABLE Tab3 AS PARTITION FOR NULL VALUES;
In this case, all nulls belong to partition "Tab3".
PARTITION System Tables
When we define partitioning rule (when we use PARTITION clause), that partition rule will be register in these system tables.
Here we can find our three merge tables. Two of them are using individual columns, and the third one is using an expression. SELECT * FROM sys.table_partitions;
Here we can find values used to determine partitions.
SELECT * FROM sys.value_partitions;
System table "sys.range_partitions" is used when partitioning is made by the ranges ( 1-100, 101-200 ).
Merge Table Based on Another Table
It is possible to give merge table definition from some other table. WITH NO DATA is mandatory. CREATE MERGE TABLE MergAS ( Letter, Number ) AS ( SELECT * FROM Tab1 ) WITH NO DATA;