Sample Table
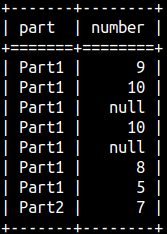 | This will be our sample table:CREATE TABLE rankFunctions ( Part CHAR(5), Number Integer ); INSERT INTO rankFunctions ( Part, Number ) VALUES ( 'Part1', 9 ), ( 'Part1', 10 ), ( 'Part1', null ), ( 'Part1', 10 ),( 'Part1', null ), ( 'Part1', 8 ),( 'Part1', 5 ), ( 'Part2', 7 ); |
Ranking Functions
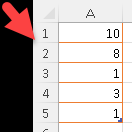 | For each row in Excel we know its row number. On the image we can see that in Excel, in front of column "A", we have a "column" with row numbers. We can create the same column, with row numbers, in MonetDB, by using ROW_NUMBER() window function. There are two more similar functions in MonetDB, and those are RANK() and DENSE_RANK(). |
 | Sometimes, in Olympic games, two sport players can share gold medal. In that case, there is no silver medal. Next best player will get bronze medal. This is called "olympic ranking". In MonetDB we can create such ranking with RANK() function. | 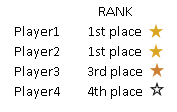 |
 | For apples we wouldn't apply Olympic ranking. Instead of that we would place apples of the similar quality in consecutive classes, so we would have apples of first, second and third class. This can be achieved with DENSE_RANK() function. As it's name implies, DENSE_RANK() doesn't have gaps in ranking, so there will be always someone who will get silver medal. |  |
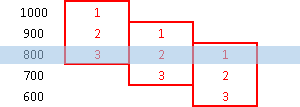 | With ROW_NUMBER(), RANK() and DENSE_RANK(), we can not use frames. These functions are not returning one value for each row, and because of that frames are not applicable. These functions always work with the whole partitions. |
This is an example for all of the three functions:SELECT part, number, ORDER BY Number; | From this example we can conlude: 1) All null values are treated as the same value. 2) It is important to use "ORDER BY" inside of WINDOW function, without it result would be meaningless. 3) These three functions are not taking any arguments. | 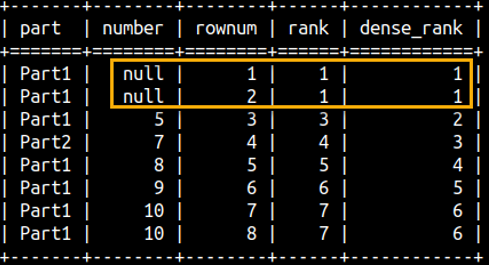 |
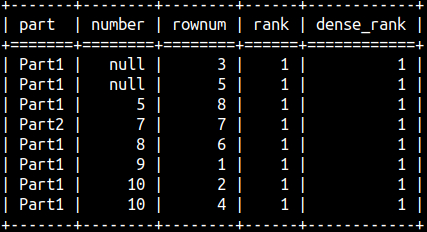 | This is what would be the result without ORDER BY. RANK and DENSE_RANK functions would return one's, so they are not really working without ORDER BY. ROW_NUMBER() function can be still be useful without ORDER BY. It can be used as a column that would deduplicate rows that are otherwise indistinguishable. | SELECT part, number, DENSE_RANK() OVER() AS dense_Rank |
| ROW_NUMBER() function is great when we want to read data step by step, by reading N consecutive rows each time. Example on the right would help us read our data by fetching 3 rows each time. | WITH Tab1 AS ( SELECT Part, Number, ROW_NUMBER() OVER (ORDER BY Number) AS RowNum FROM rankFunctions ) SELECT * FROM Tab1 WHERE RowNum BETWEEN 4 AND 6; |
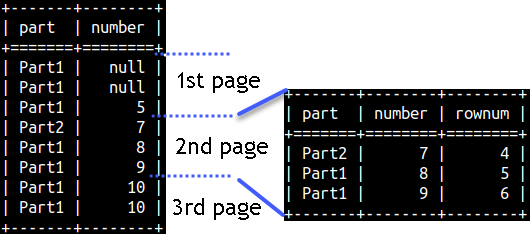 | Process of reading N by N rows is called pagination. We are reading one page at a time. |
Partitioning would just mean that we are restarting the sequence.
SELECT part, number, ROW_NUMBER() OVER(PARTITION BY Part ORDER BY Number) AS rowNum, RANK() OVER (PARTITION BY Part ORDER BY Number) AS Rank, DENSE_RANK() OVER(PARTITION BY Part ORDER BY Number) AS dense_RankFROM rankFunctions ORDER BY Part, Number; | 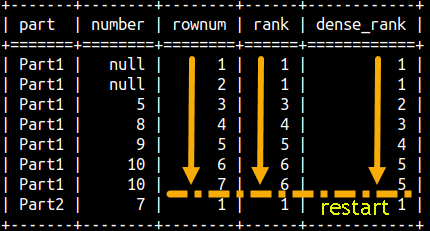 |
Relative Ranking Functions
Relative ranking functions will show us rank of a row expressed in normalized way, with numbers between 0 and 1. There are two relative ranking functions. Those are CUME_DIST() and PERCENT_RANK().
CUME_DIST() function
| CUME_DIST() is short for Cumulative Distribution. This function will can answer questions like: What percentage of screws (image on the right) is equal or smaller than 9 cm? The answer would be 4/6, that is 66%. |  | This function is called cumulative because it shows a cumulative probability.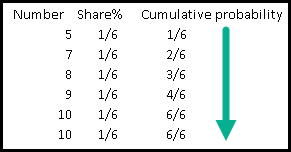 |
This would be the result for our sample table.SELECT Number, | 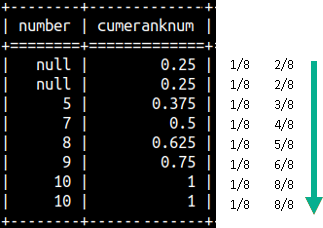 |
PERCENT_RANK() function
For PERCENT_RANK() function, we will start with an example. We can see that RANK() of Number will return numbers 1,1,3,4,5,6,7,7. PERCENT_RANK() function is similar, just the values are normalized, so it will return numbers from 0 to 1.
SELECT Number, RANK() OVER (ORDER BY Number) AS rankNum, PERCENT_RANK() OVER(ORDER BY Number) AS percRankNum FROM rankFunctions ORDER BY Number; |
PERCENT_RANK() will calculate it's values with this formula: ( rank – 1 ) PERCENT_RANK() will exclude current row from the calculation, like it doesn't exist. |
NTILE(n) Function
We have 6 screws. | We want to divide them into 2 groups. This is the most natural way to divide them:  | This is if we want to divide them into 3 groups:  |
Such separation of elements into groups can be done in SQL with NTILE(n) function. We will use NTILE(2) to divide Number column into 2 groups and NTILE(3) to divide Number columns into 3 groups.
SELECT Number, NTILE(2) OVER(ORDER BY Number) AS groupNum FROM rankFunctions ORDER BY Number; | 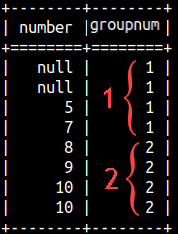 | SELECT Number, NTILE(3) OVER(ORDER BY Number) AS groupNum FROM rankFunctions ORDER BY Number; | 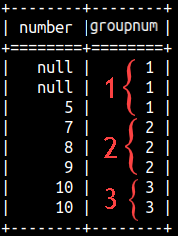 |
| We can notice that nulls would be considered as the smallest values. We can also notice that on the first image we have 2 groups with 4 Numbers. That is perfect. But, on the second image we have three groups with 3,3,2 Numbers. Groups are not of equal size. In that case we would start with 2,2,2 groups, of equal size, but the first few groups would get an extra Number. That would make things almost perfect. |  |
Final Conclusion
General rules for ranking functions are this:
| 1) All null values are treated as the same value. 2) It is important to use "ORDER BY" inside of WINDOW function, without it result would be meaningless. 3) None of the ranking functions is taking an argument, with the exception of NTILE(n) function. 4) None of these functions can work with frames, but they can use partitioning. 5) If values for several rows are the same, then the values returned by ranking functions will be the same for those rows. In our sample table, both of two rows with Number 10 will always have the same rank, no matter what ranking function we are using (except ROW_NUMBER() ). |