In order to create Python UDFs, we need to fulfill two prerequisites: – We have to install the Monetdb-Python3 package. This package is used by MonetDB to communicate with python. – We have to enable python in each database where we want to create python UDFs (monetdb set embedpy3=true).
How to provide these prerequisites is already explained in one of my previous posts ( 0360 Loader Functions In Monetdb ). Please see this blog post to learn how to enable Python support. Alternatively, you can watch video about loader functions on youtube ( https://youtu.be/2WHb41dzh_A ).
Presence of NumPy and Pandas Packages
In Ubuntu 22.04+, the global Python environment is "externally managed". That means that we have to install numpy and pandas from the official repository.
We can check whether we have numpy and pandas already installed. We don't. python3 -c "import numpy; print('NumPy installed:', numpy.__version__)" python3 -c "import pandas; print('Pandas installed:', pandas.__version__)"
Numpy and pandas are available in the ubuntu's repository. We can install them. sudo apt search python3-numpy; apt search python3-pandas
Pandas is depending on numpy, so we will first install numpy.
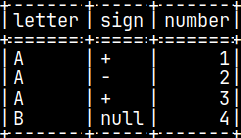
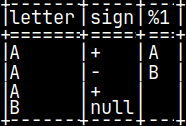
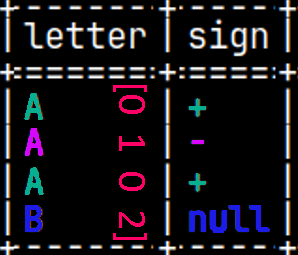
CREATE TABLE pyTab ( Letter CHAR, Sign CHAR, Number INTEGER ); INSERT INTO pyTab VALUES ( 'A', '+', 1 ), ( 'A', '-', 2 ), ( 'A', '+', 3 ), ( 'B', null, 4 ); SELECT * FROM pyTab;
Scalar Python UDF
CREATE OR REPLACE FUNCTION pyConcat(val1 CHAR, val2 CHAR) RETURNS CHAR(2) LANGUAGE PYTHON { return val1 + val2 };
This is simple function that will accept two arguments and will return their concatenation. We can use this function like this:
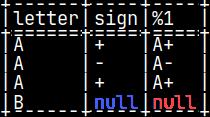
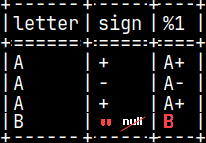
SELECT letter, sign, pyConcat( letter, sign ) FROM pyTab;
In fourth row, if "sign" is null, then the result will be null.
We can improve our function by transforming null values of the arguments into empty strings. =>
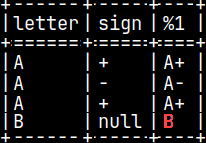
CREATE OR REPLACE FUNCTION pyConcat(val1 CHAR, val2 CHAR) RETURNS VARCHAR(2) LANGUAGE PYTHON { if isinstance(val1, numpy.ma.MaskedArray): val1 = val1.filled('') if isinstance(val2, numpy.ma.MaskedArray): val2 = val2.filled('') return val1 + val2 };
Now, we have "B" in the fourth row. This last example showed us what is the nature of arguments in python UDFs. Arguments are NumPy arrays.
import numpy as np a = np.array([1, 2, 3, 4]) print("Regular array:", a) # Regular array: [1 2 3 4]
If we have null in some column, then instead of NumPy array, we will get masked array. import numpy.ma as ma b = ma.array([1, -9999, 3, 4], mask=[False,True, False, False]) print("Sum of Masked array:", b.sum()) # Sum of Masked array: 8
A masked array is a combination of a standard NumPy array and a mask. A mask is used to hide invalid or missing values. After we hide the bad values, we can calculate the sum or average of the masked array without the influence of the bad values.
In our example, we have used "isinstance" function to examine if we have NumPy array or masked array. For masked array we have replaced bad values with empty string.
if isinstance(val2, numpy.ma.MaskedArray): val2 = val2.filled('')
If the value in the fourth row is replaced with an empty string, then the null will now affect final result.
The data type of arguments in Python is directly inferred from the SQL data types, according to this mapping.
BOOLEAN
numpy.int8
||
INTEGER
numpy.int32
||
FLOAT
numpy.float64
TINYINT
numpy.int8
||
BIGINT
numpy.int64
||
HUGEINT
numpy.float64
SMALLINT
numpy.int16
||
REAL
numpy.float32
||
STRING
numpy.object
Returned Value
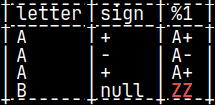
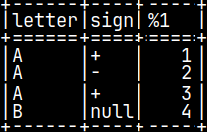
CREATE OR REPLACE FUNCTION pyConcat(val1 CHAR, val2 CHAR) RETURNS VARCHAR(2) LANGUAGE PYTHON { return(numpy.array(["A+","A-","A+","ZZ"])) };
Returned value is also NumPy array. I will create one function that will return the result as a constant. Notice that I have place "ZZ" as the last element.
This function will work just fine. We'll get our result.
SELECT letter, sign, pyConcat( letter, sign ) FROM pyTab;
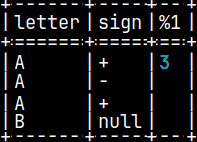
CREATE OR REPLACE FUNCTION pyConcat(val1 CHAR, val2 CHAR) RETURNS VARCHAR(2) LANGUAGE PYTHON { return( 3 ) };
This is what will happen if we return scaler.
CREATE OR REPLACE FUNCTION pyConcat(val1 CHAR, val2 CHAR) RETURNS VARCHAR(2) LANGUAGE PYTHON { return( ( 1, 2 ) ) };
If we return a tuple, we will get this message.
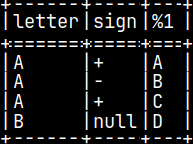
Let's try to return list, dictionary or pandas data frame. We'll call our functions with "SELECT letter, sign, Ret() FROM pyTab;".
CREATE OR REPLACE FUNCTION Ret() RETURNS CHAR LANGUAGE PYTHON { return( ['A','B','C','D'] ) };
CREATE OR REPLACE FUNCTION Ret() RETURNS CHAR LANGUAGE PYTHON { return( {"result":['A','B'] } ) };
CREATE OR REPLACE FUNCTION Ret() RETURNS INTEGER LANGUAGE PYTHON { import pandas as pd -- must import pandas return(pd.DataFrame({'result':[1,2,3,4]})) };
Python Traps
CREATE OR REPLACE FUNCTION funcCase(Letter CHAR) RETURNS CHAR LANGUAGE PYTHON { return( Letter ) };
If we try to call this function, we'll get an error. SELECT funcCase('A');
Because python is case sensitive and SQL is not, names of arguments will be turned into lower letters in python script.
Instead of "return( Letter )", we have to type "return( letter )". Arguments inside of python script have to be in lower letters.
After the change, this function will work. SELECT funcCase('A');
Python is, of course, sensitive to indentation. Indentation must be consistent. We'll get an error if it is not.
CREATE OR REPLACE FUNCTION funcIndent() RETURNS CHAR LANGUAGE PYTHON { a = 3 return a };
SELECT funcIndent();
Creating a Table with Python UDF
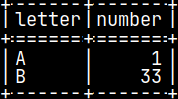
CREATE FUNCTION funcTab() RETURNS TABLE (Letter CHAR, Number INT) LANGUAGE PYTHON { result = dict() result['letter'] = ['A', 'B'] result['number'] = [1, 33] return result };
Python dictionary can be used to create table with python. SELECT * FROM funcTab();
Use Python Function to Filter Data
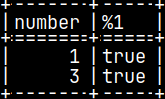
CREATE OR REPLACE FUNCTION funcBoolean(Number INT) RETURNS BOOLEAN LANGUAGE PYTHON { return number % 2 };
If python function is returning TRUE and FALSE, we can use it as a filter. SELECT Number, funcBoolean( Number ) FROM pyTab WHERE funcBoolean( Number );
Aggregate UDFs
We can group table values with this SQL statement: SELECT Letter, SUM( Number ) FROM pyTab GROUP BY Letter;
SQL statement is using built-in SQL function to aggregate values. We can do the same with python UDF. Let's make UDF function pySUM( Val ). SELECT Letter, pySUM( Number ) FROM pyTab GROUP BY Letter;
Aggregate function argument is a column to aggregate. We will use Number column. This column will be NumPy array. np.array([1, 2, 3, 4])
Beside this, aggregate function needs to know what row belongs to what group.
Groups will also be presented with a NumPy array. If we are grouping only by Letter column, our array will show that we only have 2 groups (0,1). If we group by Letter and Sign columns, then array will have 3 groups (0,1,2). This array is always one dimensional and always have the name "aggr_group".
np.array([0, 0, 0, 1])
np.array([0, 1, 0, 2])
So, inputs for our function are "val = np.array([1, 2, 3, 4])" and "aggr_group = np.array([0, 0, 0, 1])". On the left side bellow, we have our function. On the right side we can see interim results and pseudo code.
CREATE OR REPLACE AGGREGATE pySUM(val INTEGER) RETURNS INTEGER LANGUAGE PYTHON { unique = numpy.unique(aggr_group) x = numpy.zeros(shape=(unique.size)) for i in range(0, unique.size): x[i] = numpy.sum(val[aggr_group==unique[i]]) return(x) };
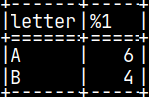
val = np.array([1, 2, 3, 4]) #we start with val and aggr_group aggr_group = np.array([0, 0, 0, 1]) unique = np.array([0, 1]) #we remove duplicates x = np.array([0, 0]) #result array, but filled with zeros for i from 0to 1#for each group x[0] = sum([1, 2, 3, 4] where [0, 0, 0, 1] = 0 ) = 6 #forA x[1] = sum([1, 2, 3, 4] where [0, 0, 0, 1] = 1 ) = 4 #forB return np.array( 6, 4 )
We will run our statement: SELECT Letter, pySUM( Number ) FROM pyTab GROUP BY Letter;
If we try to apply our function without grouping, we'll get an error. SELECT pySUM( Number ) FROM pyTab;
If there are no groups, then "aggr_group" is not defined.
CREATE OR REPLACE AGGREGATE pySUM(val INTEGER) RETURNS INTEGER LANGUAGE PYTHON { try: unique = numpy.unique(aggr_group) x = numpy.zeros(shape=(unique.size)) for i in range(0, unique.size): x[i] = numpy.sum(val[aggr_group==unique[i]]) except NameError: x = numpy.sum(val) # aggregate on all data return(x) };
We have to catch the error above with "try".
We can provide alternative result with "except NameError", that will not use "aggr_group". We will now aggregate the whole column.
SELECT pySUM( Number )FROM pyTab;
The result without grouping is 10.
System Tables
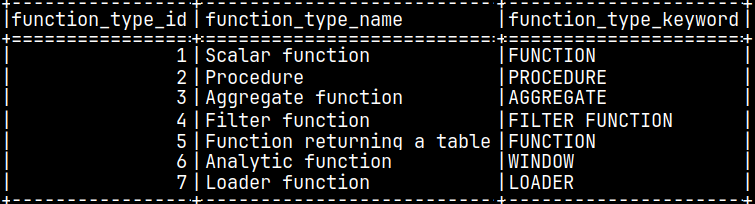
In system table "sys.function_types", we can see that aggregate functions are type 3, and scalar functions are type 1. Functions that return table are type 5.
SELECT * FROM sys.function_types;
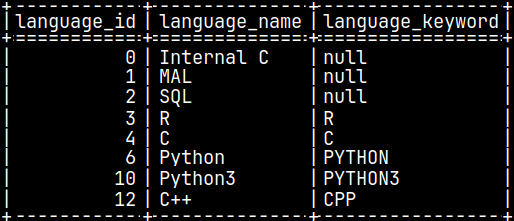
In system table "sys.function_languages", we can see what programming languages can we use to create functions.
SELECT * FROM sys.function_languages;
We can use language and function type to search for our Python functions in system table "sys.functions".