Sample Table
We will start mclient with the timer turned on. The timer will measure the time to execute the query.
mclient --timer="clock" -u voc -d voc |
Then we will create the sample table:
CREATE TABLE tblSample ( Letter VARCHAR(10) UNIQUESELECT * FROM tblSample; We can see that the query timing is 0.421 milliseconds. | 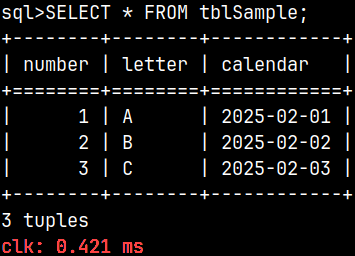 |
Inserting Data with INSERT INTO
We can insert data through some application to MonetDB, by sending INSERT INTO statements. This will work great if we don' t load a lot of rows. If we are USING a lot of consecutive INSERT statements then we can have performance issues.
INSERT INTO tblSample ( Letter, Number, Calendar ) VALUES ( 'D', 4, '2024-02-04' );
··· 1.000.000 X ···
INSERT INTO tblSample ( Letter, Number, Calendar ) VALUES ( 'ZZZZZZZ', 1000004, '2240-02-04' );We know that in MonetDB, we can insert several rows with the one INSERT statement. This will not save us, because we shouldn't use more than 20 rows per one INSERT STATEMENT. If we use more than that, we will decrease performance.
INSERT INTO tblSample ( Letter, Number, Calendar ) VALUES ( 'D', 4, '2024-02-05' )
, ( 'E', 5, '2024-02-06' )
··· 17 X ···
, ( 'F', 6, '2024-02-07' ); --20 rows at mostWe can improve performance by following these 5 advices:
- Disable autocommit. Autocommit will commit the data after each INSERT statement. If we can avoid that, we can speed up things.
- We should prepare our statement. That means that our statement will be parsed and cached once. After that, each consecutive INSERT query will use the same statement, just with another parameters.
- Use batch processing. Instead of sending a million INSERT statements, we can sent 100 batches of 10.000 INSERT statements. This will reduce communication latency between application and MonetDB, it will reduce memory usage and will minimize locking of a table.
- We should disable optimizer. Optimizer can speed up more complex statements, but there is nothing that can be improved for the simple INSERT statement.
- We can temporarily disable table constraints like primary key, foreign key or unique. We can restore those constraints after the import.
SQL benchmark
| We'll insert one row, with one INSERT INTO statement. Then we'll see if we can noticeably increase the speed by following the tips above. |
INSERT INTO tblSample ( Letter, Number, Calendar ) VALUES ( 'D', 4, '2024-02-05' ); |
 |
 | First, we will disable our optimizer.SET sys.optimizer = 'minimal_pipe'; |
In order to delete constraints, we have to found out their names. We can do that from the system tables.
SELECT T.id, T.name, C.id, C.name, K.key_id, K.key_name |  |
 | Our constraints will be temporarily removed.ALTER TABLE tblSample DROP CONSTRAINT tblsample_number_pkey; |
We will not remove constraint "NOT NULL", because that constraint will not restrain performance.
START TRANSACTION; | Now, we will start a transaction to disable autocommit. |
Then we will prepare our statement. Zero is an ID of a prepared statement. PREPARE INSERT INTO tblSample ( Letter, Number, Calendar ) VALUES ( ?, ?, ? ); |  |
After all this, we will again check the timing of our INSERT statement. We are now faster.EXECUTE 0( 'E', 5, '2024-02-06'); |  |
| The last thing is that we have to change everything the way it was. | COMMIT; -- finish transaction DEALLOCATE PREPARE ALL; -- delete prepared statement SET sys.optimizer = 'default_pipe'; -- turn on optimizer ALTER TABLE tblSample ADD UNIQUE ( Letter ); -- bring back unique constraint ALTER TABLE tblSample ADD PRIMARY KEY ( Number );-- bring back primary key constraint |
Python Benchmark
We will now try INSERT with python script. In the blog post "Connect to MonetDB from Python" we have already saw how to use python with MonetDB. Bellow is the script we will use now. This time we will insert 10 rows of data.
import pymonetdb
import time
connection = pymonetdb.connect(username="voc", password="voc", hostname="localhost", database="voc")
cursor = connection.cursor()
insert_statements = [
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('F', 6, '2024-02-06');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('G', 7, '2024-02-07');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('H', 8, '2024-02-08');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('I', 9, '2024-02-09');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('J', 10, '2024-02-10');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('K', 11, '2024-02-11');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('L', 12, '2024-02-12');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('M', 13, '2024-02-13');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('N', 14, '2024-02-14');",
"INSERT INTO tblSample (Letter, Number, Calendar) VALUES ('O', 15, '2024-02-15');",
]
overall_start_time = time.time()
for sql in insert_statements:
cursor.execute(sql)
connection.commit()
overall_end_time = time.time()
total_time = overall_end_time - overall_start_time
print(f"\n⏳ Total execution time for all inserts: {total_time:.6f} seconds")
cursor.close()
connection.close()
| Total execution time is 0.008114 seconds. |
Python Benchmark With Accelerations
We can speed up our Python script by using all of the advice mentioned in the text above. This is how our python procedure now looks like:
import pymonetdb
import time
connection = pymonetdb.connect(username="voc", password="voc", hostname="localhost", database="voc")
cursor = connection.cursor()
overall_start_time = time.time()
cursor.execute("SET sys.optimizer = 'minimal_pipe';")
cursor.execute("ALTER TABLE tblSample DROP CONSTRAINT tblsample_number_pkey;")
cursor.execute("ALTER TABLE tblSample DROP CONSTRAINT tblsample_letter_unique;")
cursor.execute("PREPARE INSERT INTO tblSample (Letter, Number, Calendar) VALUES (?, ?, ?);")
cursor.execute("SELECT * FROM sys.prepared_statements;")
preparedID = cursor.fetchone()[2]
data = [ ('P', 16, '2024-02-16'),
('Q', 17, '2024-02-17'),
('R', 18, '2024-02-18'),
('S', 19, '2024-02-19'),
('T', 20, '2024-02-20'),
('U', 21, '2024-02-21'),
('V', 22, '2024-02-22'),
('W', 23, '2024-02-23'),
('X', 24, '2024-02-24'),
('Y', 25, '2024-02-25')
]
overall_start_time = time.time()
sql="EXECUTE " + str(preparedID) + "(%s, %s, %s)"
cursor.executemany(sql, data)
connection.commit()
overall_end_time = time.time()
cursor.execute("DEALLOCATE PREPARE ALL;")
cursor.execute("SET sys.optimizer = 'default_pipe';")
cursor.execute("ALTER TABLE tblSample ADD PRIMARY KEY ( Number );")
cursor.execute("ALTER TABLE tblSample ADD UNIQUE ( Letter );")
connection.commit()
total_time = overall_end_time - overall_start_time
print(f"\n⏳ Total execution time for all inserts: {total_time:.6f} seconds")
cursor.close()
connection.close()We don't have to explicitly start a new transaction, pymonetdb will do that automatically.
| Now our timing is 0.004584 seconds. |
Timing
How to Measure Time of the Query Execution
mclient --timer="clock" -u voc -d voc | Timer can be "none" (default), "clock" or "performance". |
Bellow we can see results for these three modes of the timer switch.
mclient --timer="none" -u voc -d voc  | mclient --timer="clock" -u voc -d voc 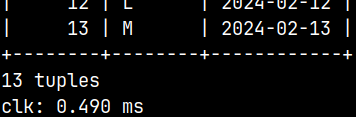 | mclient --timer="performance" -u voc -d voc 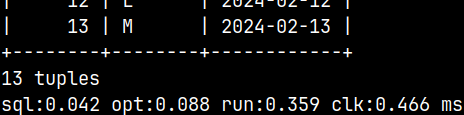 |
When we use "performance", we get 4 results. "SQL" is time used for parsing. "Opt" is time used for optimizing statement. "Run" is time used for running the statement. "Clk" is total time used.
Query History
Data about executed statements is kept in the two tables. Those two tables can be returned with functions " sys.querylog_catalog()" and "sys.querylog_calls()". In order to work with those tables we have to login as administrator.
mclient -u monetdb -d voc | Password is "monetdb". |
Data saved in these two tables is persistent between sessions. We can use procedure "sys.querylog_empty()" to clear content from those two tables.
CALL sys.querylog_empty(); –procedures are started with the "call" keyword |
In the current session we can start logging with the procedure "querylog_enable()".
CALL querylog_enable(); |
After that, I will run statement "SELECT * FROM voc.tblSample;" three times.
This will be, now, the content of the "querylog_catalog()" table.SELECT * FROM querylog_catalog();" Owner" is the user who started the query at "defined" time. |  |
We can also read from the "querylog_calls()" table.
SELECT * FROM querylog_calls();In this table we can see the " start" time and the "end" time of our query. |  |
We can stop logging or queries before the end of the session with:
CALL querylog_disable(); |
Threshold
Each time we enable logging, our logging tables will become bigger and bigger. This can make the search for a query troublesome. In order to control amount of statements that will be logged, we can use "threshold" argument.
CALL querylog_enable(5000); |
The threshold will limit the logged statements to only those whose execution time is longer than 5000 milliseconds. This allows us to perform profiling, to find the queries that are sucking up our resources the most.