Splitter functions are used as arguments in Table.SplitColumn function. Table.SplitColumn function is used to split column vertically into more columns (1 => 2). Here is the syntax and example of this function.

Table.SplitColumn(
table
, sourceColumn
, splitter function
, optional Names|Number
, optional default
, optional extraValues
) Table.SplitColumn(
TableWithColumnToSplit
, "ColumnToSplit"
, Splitter.SplitTextByDelimiter(",")
, {"A","B","C","D"}
, null
, ExtraValues.Ignore
)- table – table where is the column which we are going to split.
- sourceColumn – column that will be splitted.
- splitter function – function that explains how to split the column.
- Names | Number – names of new columns.
- default – value to place in cells which would be empty because we have more columns then values.
- extraColumns – if we have the opposite situation, number of values is bigger than the number of columns, then this argument decide what to do with extra values.
This is how we give names to new columns. If we have too many column names, extra columns will be filled with default value.
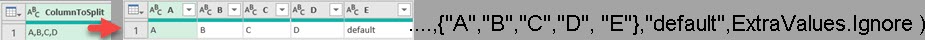
We can name columns by setting some number as fourth argument. In that case, names of columns will be generated as name of initial column + index number ( ColumnToSplit + 1,2,3 ). In the example bellow we are using number three, so there are going to be only 3 columns as a result.

If we don't have enough column names for all the columns, those columns will be missing, but only if we use "ExtraValues.Ignore" (1) as the last argument. There are two more possibilities. We can use "ExtraValues.List" (2), so last column will held all surplus values as a list. Last possibility is to raise an error. This will happen when we use "ExtraValues.Error" (3). "ExtraValues.Ignore" is default value.

Third argument is what interests us the most. It contains function that explains how to vertically slice origin column.
- Splitter.SplitByNothing
- Splitter.SplitTextByAnyDelimiter
- Splitter.SplitTextByDelimiter
- Splitter.SplitTextByEachDelimiter
- Splitter.SplitTextByLengths
- Splitter.SplitTextByPositions
- Splitter.SplitTextByRanges
- Splitter.SplitTextByRepeatedLengths
- Splitter.SplitTextByWhiteSpace
- Splitter.SplitTextByCharacterTransition
Splitter.SplitByNothing
"SplitByNothing" will not split origin column. It will only add new columns filled with default values.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitByNothing(),{"A","B","C","D"},"default",ExtraValues.Error )| ColumnToSplit | A | B | C | D | ||
| Row1 | A,B,C,D | => | A,B,C,D | defult | defult | defult |
| Row2 | A,B | => | A,B | defult | defult | defult |
If names of new columns and default value are not defined (because they are optional), then two things would still change. Name of column would change, and type of column would become "ABC 123".

Splitter.SplitTextByDelimiter
"Splitter.SplitTextByDelimiter" takes one argument. That argument is delimiter by which text will be splitted.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByDelimiter(","), { "A", "B", "C" }, "value" )Delimiter can have more than one character. Also, we can see what will happen when delimiter is at start of the text.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByDelimiter("A,"), { "A", "B", "C" }, "value" )
"SplitTextByDelimiter" accepts second optional argument. Default value for this argument is QuoteStyle.None. Difference is made when we use QuoteStyle.Csv. In that case all individual quotes will be removed ("), and double quotes will be transformed into individual quotes ("" => "). So, instead "O""A","B" we will have O"A.

Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByDelimiter( ",", QuoteStyle.Csv), { "A", "B", "C" }, "value" )Splitter.SplitTextByAnyDelimiter
Anytime we find any of the delimiters from the list in the text, we will split text. In example bellow, anytime we meet coma or semicolon, we will split the text. In table we can, also, see what will happen if there are two delimiters side by side. Two consecutive delimiters will define one empty cell. "SplitTextByAnyDelimiter" also accepts "QuoteStyle" argument.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByAnyDelimiter( { ",", ";"},QuoteStyle.None), { "A", "B", "C", "D" }, "value" )| ColumnToSplit | A | B | C | D | ||
| Row1 | A;B:C;D,E | => | A | B:C | D | E |
| Row2 | "O""A",,"B" | => | "O""A" | "B" | value |
Splitter.SplitTextByEachDelimiter
"SplitTextByEachDelimiter" is different from "SplitTextByAnyDelimiter" because now, we will split text consecutively in the same order delimiters have in their list. In our example, first we look for coma, then for colon, and then for coma again. So, if we have three delimiters in our list, we can make maximally three splits, and only if all three delimiters exist in text in proper order.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByEachDelimiter( { ",",":", ","},QuoteStyle.None), { "A", "B", "C", "D" }, "value" )| ColumnToSplit | A | B | C | D | ||
| Row1 | A,B,C:D,E;F | => | A | B,C | D | E;F |
| Row2 | A:B;C:D,E,F | => | A:B;C:D | E,F | value | value |
In second row, in table above, we can see that we only made one split. We split on the first coma, but we couldn't split on semicolon because there were no semicolons after first coma.
Splitter.SplitTextByLengths
This time, splitting is not done by delimiters but with consecutive lengths. The last number in the list is three, that is why our "D" column has value "DDD", and not "DDDD" with 4 D's. If this number was 4 (or 5 or 6…) then we would see all four D's.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByLengths( { 2, 3, 2, 3 } ), { "A", "B", "C", "D" }, "default" )| ColumnToSplit | A | B | C | D | ||
| Row1 | AABBBCCDDDD | => | AA | BBB | CC | DDD |
If we had longer list, for example { 2, 3, 2, 3, 8, 4, 2 }, nothing would change. But, if we had smaller list, for example { 2, 3 }, then last two columns would be filled with default values.
| ColumnToSplit | A | B | C | D | ||
| Row1 | AABBBCCDDDD | => | AA | BBB | default | default |
Splitter.SplitTextByPositions
Positions are positive numbers and every position can not be smaller than previous position. This positions define places where text would be splitted. In our examples we can see positions 0–11 as "0A1A2B3B4B5C6C7D8D9D10D11".
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByPositions( { 0, 2, 5, 7, 9 } ), { "A", "B", "C", "D" }, "default" )| Positions | ColumnToSplit | A | B | C | D | Where we split: | |
| {0,2,5,7,9} | AABBBCCDDDD | => | AA | BBB | CC | DD | 0A1A2B3B4B5C6C7D8D9D10D11 |
| {0,2,5} | AABBBCCDDDD | => | AA | BBB | CCDDDD | default | 0A1A2B3B4B5C6C7D8D9D10D11 |
| {0,2,2,5} | AABBBCCDDDD | => | AA | BBB | CCDDDD | 0A1A22B3B4B5C6C7D8D9D10D11 |
In first row we have position "9" which limits value in column "D" to only two D's.
In second row, we only have three positions, so the text is splitted to only three columns.
In third row, we have two same consecutive positions. This will create empty cell in column "B".
Splitter.SplitTextByRanges
In Excel, when we use function "=MID( A1; 5; 3)", we first jump to fifth character and then we take that and next two characters. This is how "SplitTextByRanges" work. Function takes argument that looks like { { 0, 2 } ,{ 3, 1 } } . Each pair of values defines position and length, the same way as MID function. In table bellow, we will see how to split text AABBBCCDDDD.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByRanges( { { 0, 2 }, { 2, 3 }, { 4, 4 } } ), { "A", "B", "C", "D" }, "default" )| Ranges | ColumnToSplit | A | B | C | D | |
| { { 0, 2 }, { 2, 3 }, { 4, 4 } } | AABBBCCDDDD | => | AA | BBB | BCCD | default |
Each pair defines one substring from initial column. Substrings can overlap. We can see that black "B" in ColumnToSplit belongs both to "B" and "C" column.
Splitter.SplitTextByRepeatedLengths
This function is similar to "SplitTextByLengths", except all lenths are of the same lenght. Here, we want to split text into groups of three characters. We can notice that last column has only two characters.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByRepeatedLengths( 3 ), { "A", "B", "C", "D" }, "default" )
Splitter.SplitTextByWhiteSpace
SplitTextByWhiteSpace is the same as SplitTextByDelimiter when delimiter is space.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByWhitespace(), { "A", "B", "C", "D" }, "default" )Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByDelimiter(" "), { "A", "B", "C" }, "value" )Splitter.SplitTextByCharacterTransition
This function accepts two arguments. Both arguments can be lists of characters. If character from first list stands before some character from the second list, then text will split between those two characters.
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByCharacterTransition( { "A", "B" }, { "B", "C" } ), { "A", "B", "C", "D", "E" }, "default" )| ColumnToSplit | Where to split | A | B | C | D | E |
| AABBBCCDDDD | AA▲B▲B▲B▲CCDDDD | AA | B | B | B | CCDDDD |
In the table above, we can see that we made a split anywhere between A and B, B and B and B and C.
We can also use functions which decide, are two consecutive characters adequate to be split between. In example bellow we have two functions. First function returns true if character is before or on "B", second function decides whether character is after "B". So this logic says that if first character is A or B, and if second character is any other letter, then split text between them (we will observe only upper letters).
Table.SplitColumn( TableWithColumnToSplit, "ColumnToSplit", Splitter.SplitTextByCharacterTransition( each if _ <= "B" then true else false, each if _ > "B" then true else false ), { "A", "B", "C" }, "default" )| ColumnToSplit | Where to split | A | B | C | |
| AABBBCCDD | AABBB▲CCDD | => | AABBB | CCDD | default |
| BBAFFF | BBA▲FFF | => | BBA | FFF | default |
| AAAGGGBBFF | AAA▲GGGBB▲FF | => | AAA | GGGBB | FF |
In table above, we can see that we made a split anywhere between B and C, A and F, A and G and B and F.
Sample file can be downloaded here:
Thanks Bizkapish , this article is much better than ms official's website.
really thanks a lot.