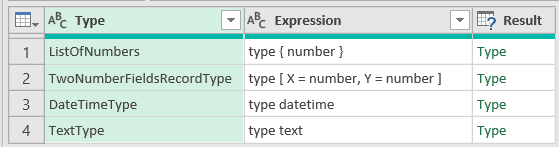
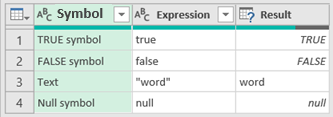
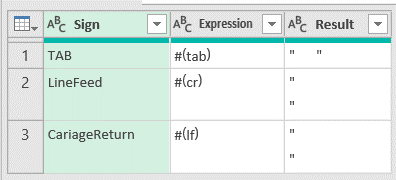
XML flattening (expanding) in Power Query
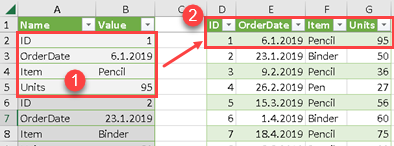
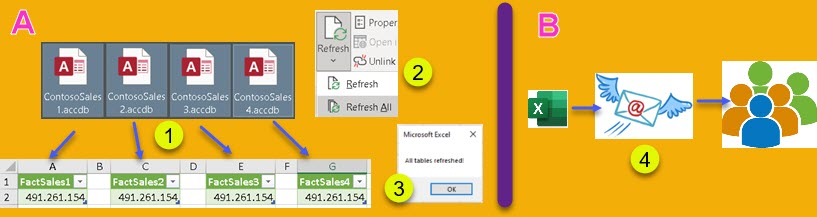
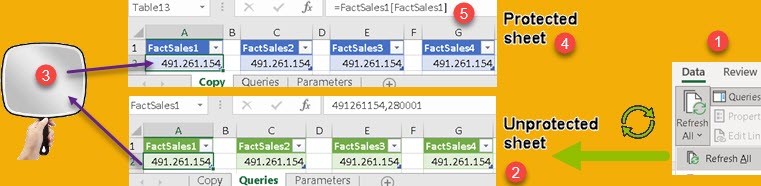
I have two XML files in folder (1). Their content is in the tables in column (2). Their content is extracted with "Xml.Document" function. If I click the Expand button (3) I could expand second column (2). After that I would have to expand the next column (4), and so on. I would end up flattening all my XML files. There are two problems with this approach. The first is that I don't want to click the expand button, I want to automatically expand all the columns (5). Another problem is that some columns may have a combination of tables and values in one column (6). In that case the expand button will not work. Let's solve this two problems.
funcIsOnlyTables
I need several helper functions to achieve my goal. funcIsOnlyTables is function which will tell me whether the only content of some column are nested tables. This function accepts two arguments – a table and a column position. This function will return TRUE if all the cells in that column have nested tables. Here, we are using function "Table.MatchesAnyRows" to see is there any cell in our column that has content that is not of type table. If that is FALSE, then our function should return TRUE, because that mean that we only have nested tables in our column.

( TableToExpand as table, ColumnNumber as number) =>
let
ColumnName = Table.ColumnNames( TableToExpand ){ColumnNumber}
, TemporaryRenaming = Table.RenameColumns( TableToExpand, { { ColumnName, "ŽŽŽ" } } )
, HasSomethingElse = Table.MatchesAnyRows( TemporaryRenaming, each not Value.Is( [ŽŽŽ], type table ) )
, HasOnlyTables = not HasSomethingElse
in
HasOnlyTables
I had to rename my column because I had to reference it somehow in "Value.Is" function.
funcIsOnlyNonTables
funcIsOnlyNonTables is similar function. It works in the same way. The only difference is that we are here looking for cells that are of type table. If there are such cells, then our function will return FALSE, because that means that our column has some cells with nested tables.

( TableToExpand as table, ColumnNumber as number) =>
let
ColumnName = Table.ColumnNames( TableToExpand ){ColumnNumber}
, PrivremenoPreimenovanje = Table.RenameColumns( TableToExpand, { { ColumnName, "ŽŽŽ" } } )
, HasTables = Table.MatchesAnyRows( PrivremenoPreimenovanje, each Value.is( [ŽŽŽ], type table ) )
, IsOnlyNonTables = not HasTables
in
IsOnlyNonTables
Residual logic
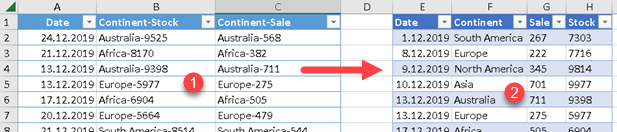
If both functions, "funcIsOnlyTables" and "funcIsOnlyNonTables" return FALSE then our column is of mixed type. It has both nested tables and values.

Now, we can discover nature of each column, so we can process each column differently based on its content.
funcExpandColumn
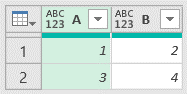
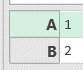
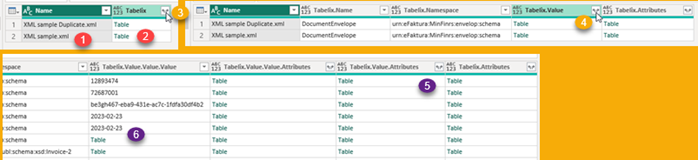
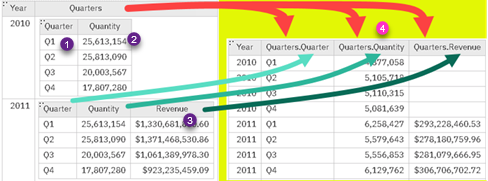
"funcExpandColumn" will expand only those columns that only have nested tables. First we have to create a list of all the names of columns in nested tables. On image, such list would be { "Quarter", "Quantity", "Revenue" } (1,2,3). We would prefix each subcolumn name with the name of original column ( "Quarters" + "." + "Quantity" (4) ), so that each newly created column has unique name. Then, it is easy to expand our column with Table.ExpandTableColumn function.
( TableToExpand as table, ColumnNumber as number) =>
let
ColumnName = Table.ColumnNames( TableToExpand ){ColumnNumber}
, TakeNamesOfSubColumns = List.Union( List.Transform( Table.Column( TableToExpand, ColumnName )
, each Table.ColumnNames( _ ) ) )
, NewNames = List.Transform( TakeNamesOfSubColumns, each ColumnName & "." & _ )
, Expanding = Table.ExpandTableColumn( TableToExpand, ColumnName, TakeNamesOfSubColumns, NewNames )
in
ExpandingfuncTabelizeExpand
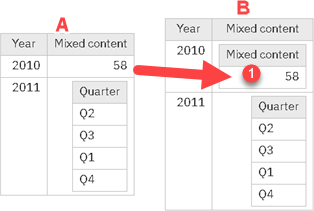
This function will solve the problem of columns with mixed content. We will transform each mixed column (A) into column where all the cells are tables (B). We will achieve that by wrapping each non table value with table that has one column and one row (1). Name of that new column (1) will be the same as the name of major column (B). Now that all the cells are filled with nested tables, we will just call function "funcExpandColumn" that we saw in the earlier step.
( TableToExpand as table, ColumnNumber as number) =>
let
ColumnName = Table.ColumnNames( TableToExpand ){ColumnNumber}
, Tabelize = Table.TransformColumns( TableToExpand, { { ColumnName, each if Value.Is( _, type table ) then _
else #table( { ColumnName }, { { _ } } ) } } )
, Expanding = funcExpandColumn( Tabelize, ColumnNumber )
in
ExpandingFinal logic
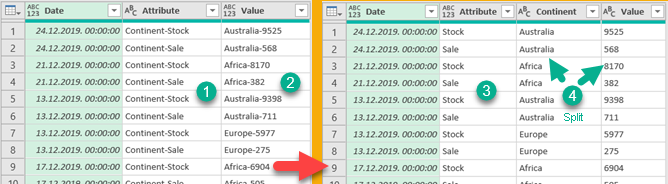
Now we have all the ingredients to flat our XML file. First we will prepare our input. Input is a table which have names of XML files, from some folder, in its first column "Name". Second column "Tabelix" has content of those files that is fetched with "Xml.Document" function.
"funcExpandAll" is the last function. This function will use all of the previous functions. This function is based on all powerfull "List.Generate" function. We will not use recursion, because "List.Generate" is faster. Logic of "List.Generate" function is similar to recursion. We have three steps:
1) First step is to establish initial conditions. TableToExpand is the table from the image above. ColumnNumber is a column of that table that will be first process, so it will be number zero.
2) Second step is condition. We will end processing of columns when we reach the last column. Note that number of columns in our table will increase with each "Table.ExpandTableColumn". This means that we don't have only two columns from the table from the image above ("Name" and "Tabelix"). As we expand columns, number of columns will increase (like on the first image in this blog post).
3) Third step is processing. In first cycle, processing is done on initial arguments TableToExpand and ColumnNumber. After first cycle, new values will be created and those new values will be input arguments for the nest cycle. Just like in recursion.
a) Here we use IF logic to decide how to process current column. If we have normal column, we want change anything. If we have column with nested tables, we will apply expansion with "funcExpandColumn". In all other cases we have mixed column. For mixed columns we will call function "funcTabelizeExpand" which will first make sure that all the values are tables and then it will call "funcExpandColumn" to finish the job. Result of the first cycle will be initial table unchanged, or it will be initial table with one column expanded.
b) We also have to change the column that will be processed in the next cycle. If we didn't work on column that had only "non table" values, then that column is just expanded and newly created column on that position could also contain nested tables. We will have to cycle through column on that position again. If our column had only normal values (numbers, strings, dates) then we can jump to the next column.
( TableToExpand as table ) =>
let
ExpandAll = List.Generate(
()=>[ TemporaryResult = TableToExpand, ColumnNumber = 0 ]
, each [ColumnNumber] < Table.ColumnCount( [TemporaryResult] )
, each [ TemporaryResult = if funcIsOnlyNonTables( [TemporaryResult], [ColumnNumber] ) then [TemporaryResult]
else if funcIsOnlyTables( [TemporaryResult], [ColumnNumber] )
then funcExpandColumn( [TemporaryResult], [ColumnNumber] )
else funcTabelizeExpand( [TemporaryResult], [ColumnNumber] )
, ColumnNumber = Iif not funcIsOnlyNonTables( [TemporaryResult], [ColumnNumber] ) then [ColumnNumber]
else [ColumnNumber] + 1 ]
, each [TemporaryResult]
)
, OnlyLastElement = List.LastN( ExpandAll, 1 ){0}
in
OnlyLastElement
"List.Generate" will return all the interim results as a list. That is why, we want to fetch only the last one.
Sample file can be downloaded from here. Just go to "XMLsInput" query to change the folder where XML files are placed on your hard disk.