Sample Table
CREATE TABLE LetterNumber( Letter CHAR, Number INTEGER ); | 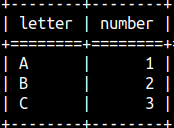 |
Views in MonetDB
Views are named and saved queries. First, we make a SELECT query, we give it a name, then we save it. Whenever we need the logic encapsulated in that query, we can get it by calling the name of a saved view. The name of a view can be now used at any place where we can use a name of a table. Views are often called "virtual tables".
| Advantages of views: – Reuse logic. This also improves consistency. – Make logic modular. – Can be used to control what users can see and what can not see. – Views can be used as intermediary between database and application. This will reduce interdependence. | Limitations of views: – Changes to underlaying base tables can invalidate views. – Proliferation of views that are mutually referenced can lead to complex structures and increased interdependency. |
CREATE VIEW voc.View1 ( Letter1, Number1 ) AS SELECT Letter, Number FROM LetterNumber WITH CHECK OPTION; | This is how we create a view. voc is the name of a schema, and View1 is the name of a view. After AS keyword, we type SELECT statement. Before the keyword AS, we type column aliases. WITH CHECK OPTION is allowed subclause, but it has no affect in MonetDB. |
We can read from the view like from a table:SELECT * FROM View1; |  |
CREATE OR REPLACE VIEW voc.View1 ( Number2, Letter2 ) AS SELECT Number, Letter FROM LetterNumber; | Subclause "OR REPLACE" can be used to change already saved view. In our example, we changed the order of columns in the SELECT statement, we also changed columns aliases. |
| Now, the result of our view will be different. |  |
Information_schemas.Views
Each database has its own system tables where it stores database metadata. These tables are different among different database servers. In order to improve standardization, SQL committee introduced standardized set of views, called "information_schemas". These views allow us to query different databases using the same queries, and to get the same metadata. These queries below will work in MonetDB, Postgres and many other databases.
SELECT schema_name, schema_owner FROM information_schema.schemata; | SELECT table_name, table_type FROM information_schema.tables; |
We are now interested in the view "Information_schemas.views". We can get information about our view with the query:
SELECT table_name, view_definition |  |
There are many more columns in this "information_schema.views" view, but we will talk about them another time.
Droping the View
| It is possible to create a view based on a view. Now we have a database object that is dependent on the View1. | CREATE VIEW View2 ( Letter3 ) AS SELECT Letter2 FROM View1; |
We will try to delete View1 with this statement, but we will fail. The reason is that View2 is dependent on the View1:DROP VIEW View1; |  |
| We can solve this in two ways. We can first delete View2 and then View1. → | DROP VIEW View2; | Other solution is to use CASCADE subclause. DROP VIEW View1 CASCADE; |
CASCADE keyword will delete View1 and all of the objects that are dependent on the view View1 (that would be View2).
If we now try to delete View1, we would get an error. DROP VIEW View1; | ||
We can avoid this error with IF EXISTS subclause. With this subclause we'll always get "operation successful". DROP | ||
What are Indexes?
 | ← At the end of a book, we have an index. An index will tell us where to look for content about a term. In the index, the terms are arranged in alphabetical order, so we can easily find a word and then look up the pages where it is mentioned in the book. ↓ It's the same with databases. Indexes will help us find our rows. In the example bellow, it is much easier to search through 2 indexes, than through 5 rows of the table. This will improve our performance.  |
Indexes will speed up data reading. Indexes must be updated when data is modified, which can slow down INSERT, UPDATE, and DELETE operations. We read data much more often than we write it, so indexes are a good approach to make our database more performant.
How to Create Indexes in MonetDB?
Great thing is that we do not have to. MonetDB will create optimal indexes for us. The user is still free to create indexes manually but those indexes will only be considered as suggestions by the MonetDB. MonetDB can freely neglect user's indexes, if it finds a better approach.
CREATE INDEX Ind1 ON voc.LetterNumber ( Letter );Voc.LetterNumber is SchemaName.TableName. The index name must be unique within the schema to which the table belongs. |
| CREATE UNIQUE INDEX Ind1 ON voc.LetterNumber ( Letter, Number ); Key word UNIQUE is allowed, but it has no affect. We can set an index on several columns. A separate index entry will then be created for each unique combination of values from those columns. → |  |
| This index will fail because we already have an index with the name Ind1. |  |
 | We can have several indexes on one table or column. These is no sense in creating several indexes, of the same type, on the same column, so we should avoid doing it. |
In sys.idxs system table we can find a list of our indexes.SELECT * FROM sys.idxs; | 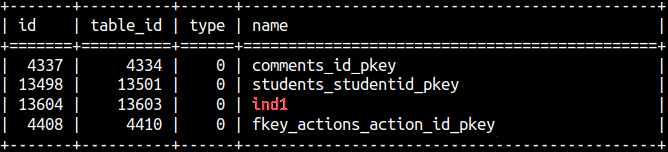 |
This is how to remove index: DROP INDEX Ind1; | All indexes are removed with this statement, including special indexes ( Imprints and Ordered index ). |
MonetDB has two special indexes: Imprints and Ordered index. These indexes are experimental and we should avoid using them.
Special Index: Ordered index
| An ordered (or clustered) index is an index where the items in the index are sorted. This makes searching through the index, filtering item ranges, and sorting table data much faster. |  |
There are some limitations on this index:
– We can use only one column for each index.
– After UPDATE, DELETE or INSERT, on the table, this index will become inactive.
The problem is that these limitations are only according to MonetDB documentation. MonetDB will NOT enforce these limitations. Below we can see an Ordered index which is using several columns, which shouldn't be allowed. This is probably the result of the fact that this index is experimental and not fully implemented.
CREATE ORDERED INDEX Ind1 ON voc.LetterNumber( Letter, Number ); |
When we create this index, it will appear in the sys.idxs table, but we can not be sure whether it is active or not. It seems that the best bet to make this index active is to:
- Make the table READ ONLY.
ALTER TABLE LetterNumber SET READ ONLY; | ALTER TABLE LetterNumber SET READ WRITE; |
- Create Ordered index on only one column.
- Don't make any further changes to that table.
Creation of this index is expensive, so we should create it ad hoc on the READ ONLY tables.
| I will delete the index we have created. | DROP INDEX Ind1; |
Special Index: Imprints Index
Imprints index is similar to Ordered index. It is experimental and not fully implemented. Some of the limitations I will talk about are not enforced by MonetDB, and they are just theoretical limitations:
- Imprints index can only be implemented on numerical and string columns.
- After UPDATE, DELETE or INSERT, on the table, this index will become inactive.
- One Imprints index can only be implemented on one column.
This index will most likely work if we apply the same steps as for the Ordered index ( READ ONLY table, one column in index, don't change nothing else ).
NOTE: From the version 11.53.3. the Imprints index on numerical columns, explained below, is removed, and is doing nothing.
The idea of the Imprints index on numerical column is to divide that column into segments, and then to store some metadata for each segment. For example, we can store minimum and maximum value for the values in one segment. If someone applies a filter "VALUE > 30", we will be able to avoid searching through segments where the maximum value is 30 or less. This will speed up our filters.

CREATE IMPRINTS INDEX Ind1 ON LetterNumber( Number ); |
The idea of the Imprints index on a string column is to make LIKE filters faster. This index would make possible to prefilter our column by using fast but not totally accurate algorithm. After that, we can apply correct algorithm on the already reduced set of data.
| In our example, Imprints index on a string column will fail, MonetDB will enforce the READ ONLY requirement this time. | CREATE IMPRINTS INDEX Ind1 ON LetterNumber( Letter);  |
After applying "ALTER TABLE LetterNumber SET READ ONLY;", our statement will still fail, because it doesn't work on the columns that have less than 5000 rows.
CREATE IMPRINTS INDEX Ind2 ON LetterNumber( Letter ); |
INSERT INTO LetterNumber ( Letter, Number ) SELECT 'G', 500 FROM CROSS JOIN (SELECT 2 FROM sys.tables LIMIT 50 ) t2; | We can insert 5.000 rows ( 'G', 500 ) into our table by the statement on the left side. In that statement, we are using one system table as a dummy table. NOTE: For this to happen we will temporarily make our table READ WRITE. |
 | Now, that our table is READ ONLY and has more than 5.000 rows, we can apply Imprints index on the Letter column. |
We will delete these indexes: DROP INDEX Ind1; | We will delete 5.000 rows from the table:ALTER TABLE LetterNumber SET READ WRITE; |