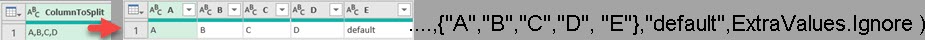Data Types in Power Query
BuiltIn Types
Power Query has built-in record with identifier #shared. This record will give us all identifiers that exist in Power Query in current context, and their types. We will transform this record into table and we will then remove this query itself from the list of identifiers, in order to avoid cyclic reference. We will filter only identifiers that represent some of Power Query types. At the end we will sort by type name.
let
IdentifiersAndTypes = Record.ToTable( #shared )
, RemoveItself = Table.SelectRows(IdentifiersAndTypes, each [Name] <> "Query1" )
, FilterOnlyTypes = Table.SelectRows( RemoveItself, each Value.Type( [Value] ) = Type.Type )
, SortTypes = Table.Sort( FilterOnlyTypes, { "Name", Order.Ascending })
in
SortTypes | #Shared (1) returned all identifiers in Power Query, together with their types. We will delete (2) the name of our query from this list in order to avoid cyclic reference. We will filter only identifiers that refer to Power Query types (3). |
Result will show us, that there are 63. built in types in Power Query. They are presented below.
| AccessControlEntry.ConditionContextType | Compression.Type | Guid.Type | MissingField.Type | RelativePosition.Type |
| AccessControlEntry.Type | CsvStyle.Type | Identity.Type | None.Type | RoundingMode.Type |
| AccessControlKind.Type | Currency.Type | IdentityProvider.Type | Null.Type | Single.Type |
| SapHanaDistribution.Type | Date.Type | Int16.Type | Number.Type | Table.Type |
| SapHanaRangeOperator.Type | DateTime.Type | Int32.Type | ODataOmitValues.Type | Text.Type |
| SapBusinessWarehouseExecutionMode.Type | DateTimeZone.Type | Int64.Type | Occurrence.Type | TextEncoding.Type |
| Any.Type | Day.Type | Int8.Type | Order.Type | Time.Type |
| Binary.Type | Decimal.Type | JoinAlgorithm.Type | Password.Type | TraceLevel.Type |
| BinaryEncoding.Type | Double.Type | JoinKind.Type | Percentage.Type | Type.Type |
| BinaryOccurrence.Type | Duration.Type | JoinSide.Type | PercentileMode.Type | Uri.Type |
| Byte.Type | ExtraValues.Type | LimitClauseKind.Type | Precision.Type | WebMethod.Type |
| ByteOrder.Type | Function.Type | List.Type | QuoteStyle.Type | |
| Character.Type | GroupKind.Type | Logical.Type | Record.Type |
Primitive types
Most of those types above are so called "ascribed types". It means that we can declare them, Power Query will remember them, but it will not enforce them. Power Query only enforce primitive types. This is list of primitive types in Power Query:
| type any | type anynonnull | type binary | type date | type datetime | type datetimezone |
| type duration | type function | type list | type logical | type null | type none |
| type number | type record | type table | type text | type time | type type |
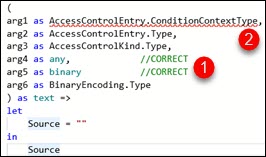 | If we try to define a function, arguments can only be declared as primitive types. We can see on the image that only primitive types any, binary, text are colored green by intelisense (1). Even the longer syntax like "Any.Type" is not acceptable. All other types (2) are incorrect and can not be used. |
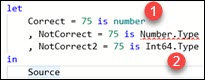 | It is the same if we want to use "is" operator. This operator will only work with primitive types ( number is green by intelisense (1) ). Even the longer syntax "Number.Type" will not work. We have to type exactly "number". |
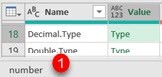 | If we select the cell with "Decimal.Type" type in our #shared table, we will see in graphic interface that this type is actually of "number" type (1). It is the same for many other types "Double.Type", "Int16.Type", "Int64.Type", "Percentage.Type" etc., "number" is their real type. |
We can create a function that will return primitive type for each of our 63. built in types in Power Query. This is the function:
( TypeToName as type ) as text =>
let
ListOfTypes = { type any, type anynonnull, type binary, type date, type datetime
, type datetimezone, type duration, type function, type list, type logical
, type null, type number, type record, type table, type text, type time, type type }
, ListOfTypeNames = { "type any", "type anynonnull", "type binary", "type date"
, "type datetime", "type datetimezone", "type duration", "type function", "type list"
, "type logical", "type null", "type number", "type record", "type table", "type text"
, "type time", "type type" }
, ZipedTypes = List.Zip( { ListOfTypes, ListOfTypeNames } )
, NameForType = List.Select( ZipedTypes, each Type.Is( _{0}, TypeToName ) ){0}{1}
in
NameForType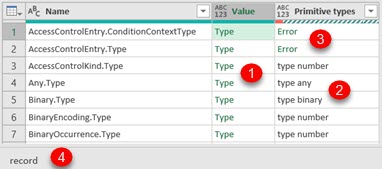 | By using the function above, we will create column "Primitive types". We can see that for each built in type (1), we can get one primitive type (2). This is true for 59/63 built in types. For some built in types (3), we will get Error. In graphic interface we can see that such types are either record or function (4). |
The reason for Error in image above is in the fact that table, function and record types are abstract types. There is no value that has type of table, function of record. We can create one table, record and function and compare their types with such abstract types, but the result will never be TRUE.
let
Table = #table( { "Column" }, { { "Value" } } )
, Record = [Field="Value"]
, Function = () => let Result = "Value" in Result
, IsTableType = Value.Type( Table ) = type table
, IsRecordType = Value.Type( Record ) = type record
, IsFunctionType = Value.Type( Function ) = type function
, IsTableTypeCompatible = Type.Is( Value.Type( Table ), type table )
in
[ IsTableType=IsTableType, IsRecordType=IsRecordType
, IsFunctionType=IsFunctionType, IsTableTypeCompatible=IsTableTypeCompatible ]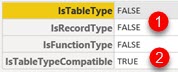 | We can see that equality will never be reached (1). But if we use "Type.Is" function to check compatibility with primitive types we will get TRUE. Compatibility means that any table is compatible with the "type table". The same is true for records and functions. |
When we declare type for function arguments, that argument will accept any value that is compatible with our declaration. If our argument is of type "number", such argument can receive values of all the compatible types "Double.Type", "Int16.Type", "Int64.Type", "Percentage.Type" etc.
How to check ascribed type
We will create three values of type Int64.Type, Decimal.Type and Text.Type. The question is how to read ascribed types of this values. We can do that from "metadata".
let
Int64Type = Value.ReplaceType( 99, Int64.Type )
, DecimalType = Value.ReplaceType( 99.99, Decimal.Type )
, TextType = Value.ReplaceType( "hundred", Text.Type )
, OneTable = #table( { "values" }, { { Int64Type }, { DecimalType }, { TextType } } )
, AddMetadata = Table.AddColumn( OneTable, "Metadata"
, each Value.Metadata( Value.Type( [values] ) ) )
, AddAscribedTypeName = Table.AddColumn( AddMetadata, "AscribedTypeName"
, each [Metadata][Documentation.Name] )
in
AddAscribedTypeName  | Value.Metadata function will return record which has Documentation.Name fild which contains ascribed type name. This is where Power Query store information about ascribed types. |
Sample file can be downloaded here: