Let's create test table:
1) CREATE TABLE samplingTable ( Letter CHAR, Number INTEGER );
2) INSERT INTO samplingTable ( Letter, Number )
VALUES ( 'A', 1 ), ( 'B', 2 ), ( 'C', 3 ), ( 'D', 4 ), ( 'E', 5 )
, ( 'F', 6 ), ( 'G', 7 ), ( 'H', 8 ), ( 'I', 9 ), ( 'J', 10 );
Two Ways of Sampling
Sampling of records is done with SAMPLE clause. This clause accepts continuous range [0,1) as an argument. Selected number is percent of records that will become part of the sample. It is also possible to select any integer bigger than zero. That number will become number of units in the sample.
SELECT * FROM samplingTable SAMPLE 0.2; --20% | SELECT * FROM samplingTable SAMPLE 3; --3 units | SELECT * FROM samplingTable SAMPLE 1; --1 unit |
 |  |  |
It is possible to sample from a subquery.SELECT * FROM | It is possible to use sample in an INSERT statement.INSERT INTO samplingTableSELECT * FROM samplingTable SAMPLE 2; |
Samples have uniform distribution.
Table Statistics
Statistics System Table
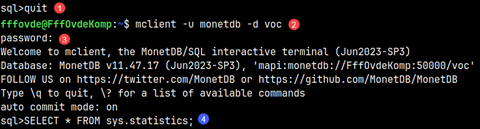
Statistics about tables is placed in the table sys.statistics. In order to read from this system table, we have to log in as an administrator monetdb.
First, we quit current session (1). Then we have to log in as a monetdb (2). Password is "monetdb" (3). Then, we are allowed to read from statistics table (4).
These are the columns in that table:
| column_id | schema | table | column | type | width | count | unique | nils | minval | maxval | sorted | revsorted |
| INTEGER | VARCHAR | VARCHAR | VARCHAR | VARCHAR | INTEGER | BIGINT | BOOLEAN | BOOLEAN | CLOB | CLOB | BOOLEAN | BOOLEAN |
| Internal ID of column. | Schema name. | Table name. | Column name. | Data type of column. | Number of bytes. | Number or rows, approximate. | Are values unique in column. | True, if there are nulls in column. | Minimum in the column or null. | Maximum in the column or null. | Column sorted ascending. | Column sorted descending. |

All the strings from this table are small case. When we refer to them, we have to write them exactly like in the table.
SELECT * FROM sys.statistics WHERE COLUMN = 'Letter'; | This will fail because we have to use lower letters for 'letter'. |
Table Producing Functions
Table sys.statistics will give us statistics about all of the user tables in our schema. If we want to read statistics of system tables too, then we should use this table producing function.
SELECT * FROM |  |
For reading statistics for one schema, table, or column, we can filter sys.statistics or sys.statistics() tables. Instead of filtering, we should use these table producing functions with arguments which define what data we want to read. This table producing functions are fastest way to get specific statistics.
SELECT * FROM sys.statistics('voc'); Statistics for a schema. | SELECT * FROMsys.statistics( 'voc','samplingtable'); Arguments are case sensitive. Statistics for a table. | SELECT FROM sys.statistics('voc','samplingtable','letter'); Statistics for a column. |
Refreshing Statistics
We can refresh statistics for the whole schema, for the one table, or for the one column. The refresh will take a long time if we have a lot of data.
ANALYZE voc; --whole schema | ANALYZE voc.samplingtable; --one table | ANALYZE voc.samplingtable ( letter ); --one column |
Statistics is used by MonetDB, to optimize queries. If we made a lot of deletes, inserts or updates, statistics will become obsolete so we should refresh it. This will make our queries performant again.
Prepare Statement
If we want to use some statement many times, we can prepare it as well. That means that executing plan for that statement will be cached during the session. Each sequential call of that statement will use cached version, but with different parameters.
As a monetdb user, our default schema is sys. Before going through example, we will first change our current schema to voc.
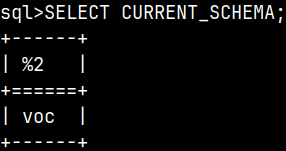 | Now, instead of voc.samplingTable, we can just type samplingTable. |
For example, let's say that we want to insert three rows in our table samplingTable. For that we can use three separate statements.
INSERT INTO samplingTable ( Letter, Number ) VALUES ( 'O', 100 );
INSERT INTO samplingTable ( Letter, Number ) VALUES ( 'P', 101 );
INSERT INTO samplingTable ( Letter, Number ) VALUES ( 'Q', 102 );
For each of these statements, MonetDB will create separate execution plan. To avoid doing the same work three times, we will prepare this statement.
Instead of parameters, we will use question marks. They are placeholders for real values.PREPARE INSERT INTO samplingTable ( Letter, Number ) VALUES ( ?, ? );Zero, from the image on the right, is an ID of our prepared statement. We can use that ID to call our prepared statement. |  |
We will now execute our three statements from above, by using this prepared statement. Zero is ID of our prepared statement.
EXECUTE 0( '0', 100);EXECUTE 0( 'P', 101); | This will insert three new rows in samplingTable. |  |
| Data about our prepared statements is in the system table sys.prepared_statements. |  |
We can release this prepared statement from our session cache.
DEALLOCATE PREPARE 0; --This will remove just prepared statement with ID 0. --This will remove all prepared statements. |
Prepared statements will be deleted automatically, if any error happens during the user session. If the error doesn't occur and we do not use "DEALLOCATE" then the prepare statements will all be deleted when we exit the session.