How to create new variables in SPSS
We have three columns with the scores of a judges (1). We want to create new column that will present an average score (2). For this, we are using option Transform > Compute Variable (3). This will open form where we can define new variable.

In new dialog, first thing is to give name to new variable (1). Button (2) can open small dialog where we can define label (3) for our variable. That label is just description of a variable. We can also define our variable as Numeric or String type (4). In this case, we will choose "Numeric". Pane (6) is where we create expression for new variable. This expression is comprised of column names, mathematical operators, builtin functions and constants. We can type the whole expression from our keyboard, but instead of typing we can just select some building blocks for our expression from other areas in this dialog, and they will appear in pane (6).
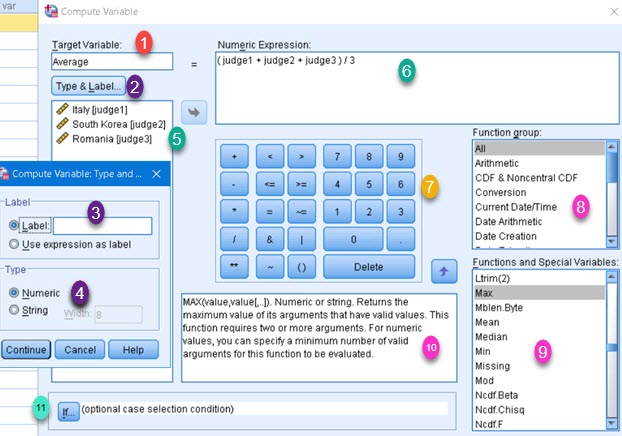
Pane (5) has names of all the columns. Pane (9) has names of functions. Virtual keyboard (7) allows us to type different signs and numbers by using mouse. We can use all those elements to create desired expression in pane (6).
By selecting some of functions groups in pane (8), we can limit what functions will be presented in pane (9).
When some of functions in pane (9) is selected, we will be able to see its syntax and description in pane (10).
We created formula (6). The formula "MEAN (judge1, judge2, judge3)" would give us the same result.
When we click on column name, that column name will appear in our expression: 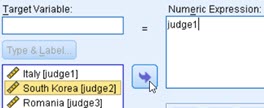 | By using virtual keyboard we can add different operators and numbers to our expression.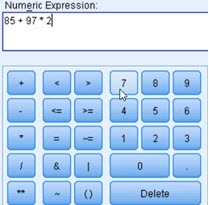 | Clicking on some of functions will add syntax for that function in expression pane. Then we'll have to replace question marks with functions arguments. Those arguments can be column names, constants or subexpressions.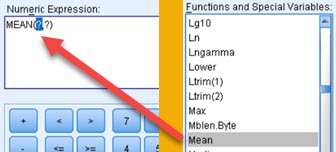 |
In virtual keyboard we have signs "**", "&", "|". Sign "&" is for logical AND. Sign "|" is for logical OR. When we write "2**3", it is the same as "23".
Conditional variables
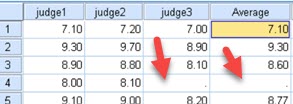
If some of values, in columns that we used to calculate our new variable, are missing, then the value in the same row will not be calculated for our new variable (only for our original expression, it seems that builtin MEAN function is resistant to this). Missing value will be presented with a dot.
If we have all the values in columns judge1, judge2, judge3, it is still possible to make variable with missing values. Example bellow shows how to do it.
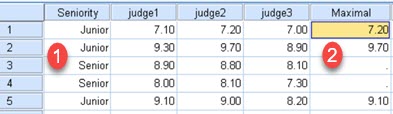
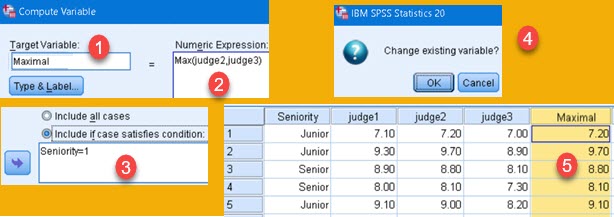
Now we have one column more (1). This column shows, whether scores belong to junior or senior competitor. We want to create new variable that will present maximal value, but only for junior competitors (2). We can achieve this with conditional variables. First we create formula for our variable. We are going to use MAX function (3). Then we have to define condition. Place for that is opened by clicking on "If" button on the bottom of the main dialog (4).
MAX(judge1,judge2,judge3) (3)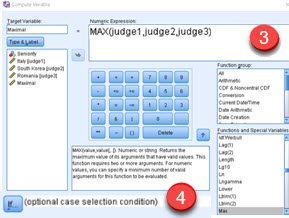
We will be greeted with a dialog where on the top we have to select option "Include If case satisfies condition" (1).
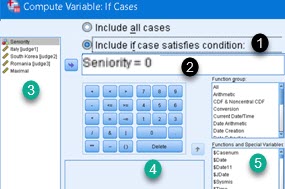
In pane (2) we have to enter condition. In every row where this condition is satisfied, new variable will have a value, and vice versa. Way of creating condition is similar as way of creating expression for new variable. We have columns (3), functions (5) and buttons (4) to help us create this boolean expression.
Our junior competitors are coded with number "0" (Seniors are "1"). This makes our conditional expression as simple as:
Seniority = 0This is all if we want only "Junior" rows filled with values for new variable.
After this, we can create new variable with the same name (1). This variable will calculate maximal score for judge2 and judge3 (2), but only for Senior competitors (3). For some reason, we will consider scores of judge1 invalid for Senior competitors. SPSS will ask us whether we want to change existing variable (4). We'll click on YES. SPSS will not overwrite old column with new column. It will combine them. We can see in (5) that all rows are populated. Rows 1, 2 and 5 are for Junior competitors and they show maximum for "judge1,judge2,judge3". Rows 3 and 4 are for Senior competitors and they show maximum for "judge2,judge3". In row 3 we can see that the value in "Maximal" column is 8.8, which is maximum for columns "judge2,judge3". Total maximum is 8.9, but that maximum is in column judge1 that does not count.
We can continue to add more conditional variables with the same name. Each new variable will overwrite only results which satisfy its condition. If we add third variable with name "Maximal" and condition "judge2>8", it will only overwrite values in rows where this condition is fullfilled.
Two caveats to consider
- When we click on some function, its syntax will be added to expression pane. If we click on MAX function, syntax like this will be added "MAX(?,?)". This doesn't mean that this function can have only two arguments. It can have infinite number of arguments "MAX(a,b,c,d,e…)", but we have to type other arguments by hand. Same for many other functions.
- When we create new variable, we can give it the same name as one of original columns. For example, we have original column "judge1", and we create new variable with the same name "judge1". SPSS will ask us whether to change existing variable. If we click on YES, we are going to lose original column. New variable will overwrite original variable.
Here is a sample file: