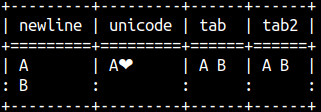
By placing letter e before string, we can write control characters ( Tab, New line, Carriage return ) with their specifiers. This will work even without e.
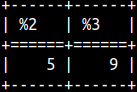
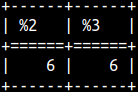
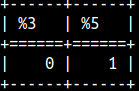
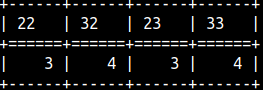
select e'A\nB' AS NewLine , e'A\u2764' AS Unicode , e'A\tB'AS TAB , 'A\tB'AS TAB2;
Control Character
Name
Usage
\n
Newline
Moves the cursor to the next line.
\r
Carriage return
Moves the cursor to the beginning of the current line.
\t
Tab space
Inserts a tab space.
\b
Backspace
Deletes the character just before the control character.
\f
Form feed
Moves the cursor to the next page.
\u
Unicode character
Represents a Unicode character using a code number.
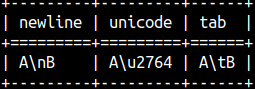
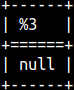
Without e, the result is the same ( e'A\tB' = 'A\tB' ). If we want to write literal specifiers, then we have to use prefix R.
select r'A\nB' AS NewLine, r'A\u2764' AS Unicode, R'A\tB'AS TAB;
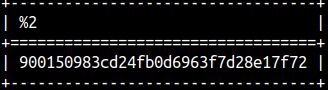
We can write blob with pairs of hexadecimal characters. Before such blob we should type X or blob.
SELECT x'12AB', blob '12AB';
Concatenation
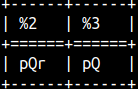
Concatenation can be done with operator || or with concat function. Concat function accepts only 2 arguments.
SELECT 'p' || 'Q' || 'R', concat( 'p', 'Q' );
Number of Characters
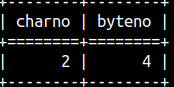
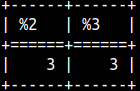
Length function returns number of characters. Synonims for length function are char_length and character_length. MonetDB encode all of the strings with UTF-8. Some of UTF-8 characters use several bytes. If we want to know length of a string in bytes then we should use octet_length function.
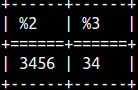
SELECT length(R'2€') AS CharNo, octet_length(R'2€') AS ByteNo;
Searching for One String Within Another
In our example, LOCATE looks for the substring 'es' within the second argument. If it can find it, LOCATE will return in what position. SELECT LOCATE( 'es', 'successlessness' ), LOCATE( 'es', 'successlessness', 8 ); We can give a third argument. In our example, we will not search for 'es' in the first 8 characters. Synonym for this function is CHARINDEX.
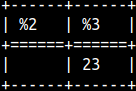
POSITION function will also return position of the substring 'es'. SELECT POSITION( 'es' IN 'successlessness' );
PATINDEX function is similar. Difference is that this function can use wildcards. It can use '%' for zero or more characters or '_' for one character. It will return position, not of the first letter, but of the last letter. SELECT PATINDEX( '%eS', 'succeSslessness' ),PATINDEX( '____eS', 'succeSslessness' );
All of these functions (LOCATE, CHARINDEX, POSITION, PATINDEX) are case sensitive. SELECT CHARINDEX( 'ES', 'successlessness' ); If they can not find substring, all of them will return zero.
Get the Substring by its Position
SUBSTRING function will return all the letters of the string after some position. SELECT SUBSTRING( '123456', 3 ), SUBSTRING( '123456', 3, 2 ) ; With the third argument, we can limit number of characters returned.
If the second argument is too large, we will get an empty string. SELECT SUBSTRING( '123', 5 ), SUBSTRING( '123', 2, 7 ) ; If the third argument is too large, it will have no effect.
Instead of SUBSTRING, we can use SUBSTR.
Convert Case
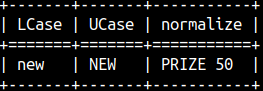
LCASE will transform the string to lower case. UCASE to upper case. Synonyms are LOWER and UPPER. SELECT LCASE( 'NEW' ), UCASE( 'new' ), QGRAMNORMALIZE ('Prize €50!'); Special function QGRAMNORMALIZE will transform the string to upper case while removing all the strange characters, only numbers and letters will remain.
Max and Min
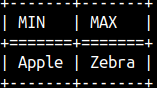
We can order words alphabetically ( Apple, Zebra ). Minimum function will return the word closer to "A", and maximum function will return the word closer to "Z". SELECT sql_min( 'Apple', 'Zebra' ) AS "MIN", sql_max( 'Apple', 'Zebra' ) AS "MAX"; Synonyms for these functions are LEAST and GREATEST.
Unicode and ASCII
ASCII function will return Unicode number of the first character of the string (ß=>223). CODE function will return the opposite, for the Unicode number, it will return the character (223=>ß). ASCIIFY function will transform all of the non-ascii characters to ascii equivalents (€=>EUR). SELECT ASCII( r'ßzebra' ) AS FirstLetterUnicode , CODE( 223 ) AS UnicodeCharacter , ASCIIFY( R'a € sign' ) AS AsciiOnly;
Padding of The String
We can pad some string with spaces from the left, or from the right side. Second argument decides what should be the length of the whole string. SELECT '=>' || LPAD( 'zz', 5 ) AS LeftPadding , RPAD( 'zz', 5 ) || '<=' AS RightPadding;
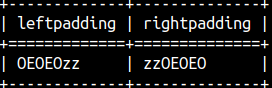
If used, third argument will be used instead of the space sign. SELECT LPAD( 'zz', 7, 'OE' ) AS LeftPadding, RPAD( 'zz', 7, 'OE' ) AS RightPadding;
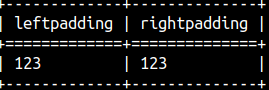
If the string is already too long, then it will be truncated from the right side. SELECT LPAD( '12345', 3 ) AS LeftPadding , RPAD( '12345', 3 ) AS RightPadding;
Trimming The String
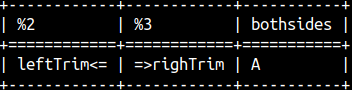
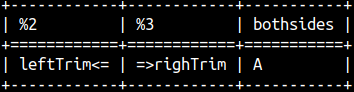
We can trim spaces from the start, from the end, or from the both ends of a string. SELECT 'leftTrim' || LTRIM( ' <=' ) , RTRIM( '=> ' ) || 'righTrim' , TRIM( ' A ' ) AS BothSides;
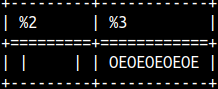
The second argument can be used to specify the string to trim. SELECT 'leftTrim' || LTRIM( 'UUU<=', 'UU' ) , RTRIM( '=>UUU', 'UU' ) || 'righTrim' , TRIM( 'zzAzz', 'z' ) AS BothSides;
String Repetition
With SPACE function we can repeat space character many times. With REPEAT function we can repeat any string many times. SELECT '|' || SPACE(5) || '|', REPEAT( 'OE', 5);
Extracting the Start or End of the String
This is how we can get the first or last two characters. SELECT LEFT( '1234', 2 ), RIGHT( '1234', 2 );
Guess the Start or the End of the String
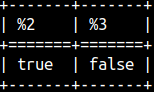
This is how we can check if the string starts or ends with some other string. SELECT startswith( 'ABC', 'AB' ), endswith( 'ABC', 'bC' );
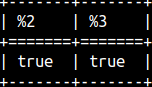
If we want to make comparison case insensitive, then we have to provide TRUE for the third argument. SELECT startswith( 'ABC', 'ab', true ), endswith( 'ABC', 'bC', true );
Does One String Contains Another
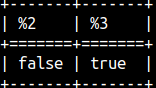
CONTAINS function will check whether second string is contained inside of the first string. The function is case sensitive. We can make it insensitive by adding third argument TRUE.
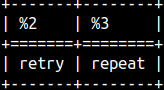
REPLACE function will search for the second string inside of the first string. It will replace it with the third string. This function is case sensitive. SELECT REPLACE( 'repeat', 'peat', 'try' ), REPLACE( 'repeat', 'PEAT', 'try' );
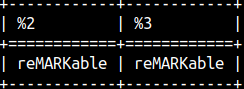
INSERT function will remove characters between positions 3 (2 + 1) and 6 (2 + 4). It will replace them with the last argument. In the second column, it will search between positions 3 (10 – 8 + 1) and 6 again, but this time it is counting from the end. SELECT INSERT( 'remarkable', 2, 4, 'MARK' ), INSERT( 'remarkable', -8, 4, 'MARK' );
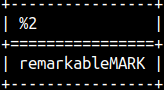
If the second argument, in INSERT function, is too big, then the string will get a suffix. SELECT INSERT( 'remarkable', 50, 4, 'MARK' );
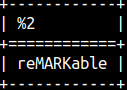
SYS.MS_STUFF function is similar to INSERT function. Main difference is that for the second argument we have to provide the exact position. Instead of 2 we have to provide exact 3. SELECT sys.ms_stuff( 'remarkable', 3, 4, 'MARK' );
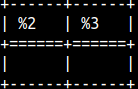
If we make a mistake with the second argument, while using SYS.MS_STUFF function, we will get an empty string as a result. SELECT sys.ms_stuff( 'remarkable', -3, 1, 'MARK' ), sys.ms_stuff( 'remarkable', 50, 1, 'MARK' );
Interesting thing with the SYS.MS_STUFF function is that the third argument can be negative. This argument will then duplicate several last characters from the start of the string. SELECT sys.ms_stuff( 'remarkable', 3, 0, 'MARK' ) AS "0" --reMARKmarkable , sys.ms_stuff( 'remarkable', 3, -1, 'MARK' ) AS "-1" --reMARKemarkable , sys.ms_stuff( 'remarkable', 3, -2, 'MARK' ) AS "-2"; --reMARKremarkable
Find a String in the List
FIELD function can have unlimited number of arguments. First argument is the string we are searching for. All other arguments are a list in which we are searching. The result will be the position of the first string in that list. That position is zero based. SELECT FIELD( 'A', 'A', 'B', 'C' ), FIELD( 'B', 'A', 'B', 'C' );
Search is case sensitive. If we can not find the string, the result will be NULL. SELECT FIELD( 'z', 'A', 'B', 'C' );
Other Functions
With sys.md5 function we will calculate a hash of a string. Hush will have 32 hexadecimal characters. SELECT sys.md5('abc');
SPLITPART function will split the string by its delimiter. That will transform the string into list. From that list we will take the third element. SELECT SPLITPART( 'a1||b2||cd3||ef4', '||', 3);
Blob Functions
We have two functions to return the size of a BLOB in bytes. They are the same function. SELECT length(x'0012FF'), octet_length(x'0012FF');
String Similarity
Before calculating similarity between two strings, we should standardize those strings as much as possible. In MonetDB, we can achieve that with QGRAMNORMALIZE function.
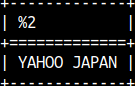
QGRAMNORMALIZE function will remove everything accept letters and numbers. All letters will be transformed into uppercase. SELECT QGRAMNORMALIZE('Yahoo! Japan');
In order to transform word "kitten" into word "sitting" we need one insert, and two updates.
kitten -> ("k" to "s" update) -> sitten -> ( "e" to "i" update ) -> sittin -> ( add "g" on end ) -> sitting
If the "price" of each step is 1, the full price for 3 steps is 3. We can get number of steps with Levenshtein function. That is how we measure similarity of words. Deletes would be also counted as 1.
SELECT LEVENSHTEIN('kitten','sitting');
The DAMERAU-LEVENSHTEIN function is similar to the LEVENSHTEIN function. The difference is that DAMERAU-LEWENSTEIN also takes transpositions into account. In the DAMERAU-LEVENSHTEIN function, "AC" -> "CA" is only one step. In the LEVENSHTEIN function, we would have to update two letters, so that transformation would be 2 steps.
It seems that in MonetDB, these two functions are the same, and the behavior is controlled by the number of the arguments.
If we want to achieve the behavior of the DAMERAU-LEVENSHTEIN function, we have to provide 5 arguments. Last three arguments are in order: costs for insert/delete, substitution, transposition.
But the result is still only 2. That is because we can achieve the same result in three ways. AC -> (transposition) -> CA --cost would be 3 steps AC -> (remove A) -> C -> (add A) -> CA --only 2 steps AC -> (update A>C) -> CC -> (update C>A) -> CA --again 2 steps We will always get the smallest metric.
There is also a version of the LEVENSHTEIN function with 4 arguments. In this function, default cost for the insert is 1. Third argument is DELETE, forth is REPLACE. Transposition is not possible in this case, so it will not act as a DAMERAULEVENSHTEIN function.
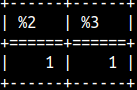
EDITDISTANCE is the same as DAMERAULEVENSHTEIN. Everything cost 1 point, but transposition costs 2 points. SELECT EDITDISTANCE( 'AC', 'CA' );
EDITDISTANCE2 is the same as DAMERAULEVENSHTEIN. Everything cost 1 point. SELECT EDITDISTANCE2( 'AC', 'CA' );
Jaro-Winkler function
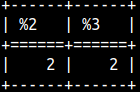
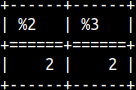
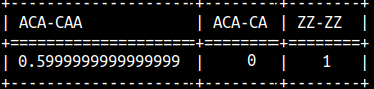
Jaro-Winkler function will compare two strings. If they are the same, result will be 1, if they are totally different, result will be 0. These functions will give bigger result to strings which have the same prefix. The bigger the prefix, the bigger the boost will be. SELECT JAROWINKLER('ACA','CAA') AS "ACA-CAA" , JAROWINKLER('ACA','CA') AS "ACA-CA" , JAROWINKLER('ZZ','ZZ') AS "ZZ-ZZ";
Soundex
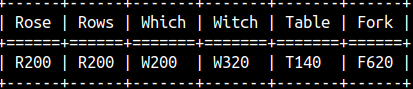
SOUNDEX function works only for English language. SOUNDEX function will transform a string to number. That number depicts how that word would be pronounced in the English language. If two words have the same pronunciation, then SOUNDEX function will return the same number for those 2 words. SELECT SOUNDEX('Rose') AS "Rose", SOUNDEX('Rows') AS "Rows" , SOUNDEX('Which') AS "Which", SOUNDEX('Witch') AS "Witch" , SOUNDEX('Table') AS "Table", SOUNDEX('Fork') AS "Fork";
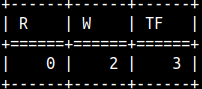
Soundex result is made of the starting letter of the word, and three numbers. If two words have the same SOUNDEX code, then DIFFERENCE function would return 0, because there would be 0 differences. SELECT DIFFERENCE('Rose', 'Rows') AS "R", --R200 vs R200 => 0 DIFFERENCE('Which', 'Witch') AS "W", --W200 vs W320 => 2 DIFFERENCE('Table', 'Fork') AS "TF"; --T140 vs F620 => 3
So, the result of the DIFFERENCE function can be between 0 and 4.