Sample tables
We will create these two tables in the MonetDB database:
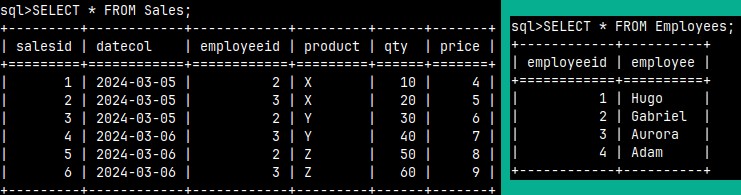
We can create these two tables using these statements. The first statement will create the table. The second statement will populate that table with data.
1) CREATE TABLE Employees ( EmployeeID INT, Employee VARCHAR(10 ) );2) INSERT INTO Employees ( EmployeeID, Employee ) VALUES ( 1, 'Hugo' ), ( 2, 'Gabriel' ), ( 3, 'Aurora' ), ( 4, 'Adam' ); |
1) CREATE TABLE Sales ( SalesID INT, DateCol DATE, EmployeeID INT, Product CHAR(1), Qty INTEGER, Price INTEGER );2) INSERT INTO Sales ( SalesID, DateCol, EmployeeID, Product, Qty, Price ) VALUES; |
Simple SELECT statement
The simplest SELECT statement will read the entire table. The star "*" is a symbol that represents all columns. This statement will read all columns and all rows from the table.SELECT * FROM Employees; |  |
If we don't need all the columns, we have to specify them. After the SELECT keyword, we need to type the list of columns we want to read. Only those columns will be fetched.SELECT Product, Qty FROM Sales; | 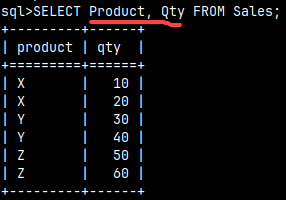 |
If we want to rename columns, we can use "AS Alias" after the column name.SELECT EmployeeID AS ID, Employee AS Name FROM Employees; | 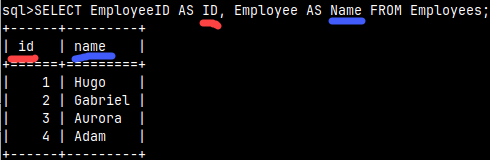 |
We don't need a table for our SELECT statement. We can use expressions to create values. If we don't provide aliases for these expressions, their columns will have generic names like "%2, %3, %4".SELECT 3+3, CURRENT_DATE; |  |
We can combine columns and expressions.SELECT Employee, CURRENT_DATE as Today FROM Employees; | 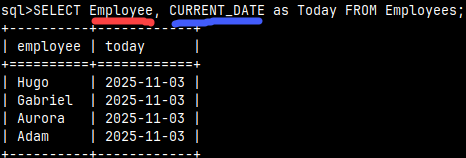 |
An expression can reference values from columns. In our example, the Multiplication column is calculated by multiplying the value from the EmploeeID column by 11. If we put double quotes around the alias "Multiplication", then this alias will preserve its case in the result. Otherwise, it will be written in lowercase letters.SELECT EmployeeID, EmployeeID * 11 AS "Multiplication" FROM Employees; | 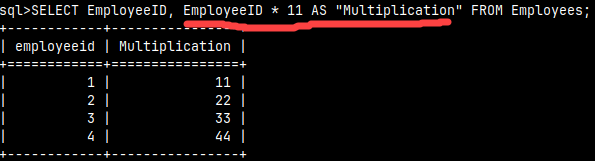 |
Reminder of the Identifiers
If we create a table with double quotes, like CREATE TABLE Tab1 ( "Col1" CHAR ), then the header of this table will be like this:
 | The column name will be case sensitive. This will force us to write the SELECT statement with double quotes as well. If we omitted the double quotes, our SELECT statement would not work. If we want our column name to have any non-standard characters or spaces, then we would always have to use double quotes. |
Filtering and Ordering Rows
After the FROM clause we can use WHERE. With WHERE we can define a condition that will filter only matching rows. Within that expression we can reference any column. Expressions can be much more complex than this.SELECT * FROM Employees WHERE EmployeeID >= 3; |  |
The server will read rows from the table in a way that achieves the best performance. We don't know in advance the order in which the server will read the records, so we should make the server sort the result using the ORDER statement. The ORDER command will have a list of columns by which the rows will be sorted. We can sort using ASC or DESC order, but ASC is the default. The table will be sorted first by EmploeeID and then by Qty, so the order of the columns in the ORDER statement is important.SELECT * FROM Sales ORDER BY EmployeeID DESC, Qty; | 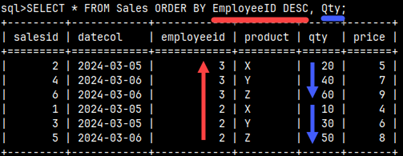 |
If we add DISTINCT to our statement, we will remove duplicate rows.SELECT Product FROM Sales; 6 rowsSELECT DISTINCT Product FROM Sales; 3 rows | 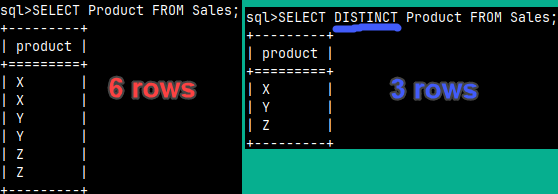 |
We can limit the number of rows we want the server to return. For that we use the keywords LIMIT and OFFSET. We will also use ORDER BY in this example to better understand what MonetDB did. MonetDB will skip one row and then read the next two rows.SELECT * FROM Employees ORDER BY EmployeeID LIMIT 2 OFFSET 1; |  |
| Using only LIMIT, we can read a limited number of lines from the beginning. Using only OFFSET, we can read everything except the lines at the beginning. |  |
Grouping our Data
If we want to remove duplicates from our columns, we can use GROUP BY. In this simplest case, we must mention all columns after both SELECT and GROUP BY. This result could be made much easier with the DISTINCT keyword. In practice we use GROUP BY to achieve something different and this will become clearer in the example below.SELECT DateCol, EmployeeID FROM SALES GROUP BY DateCol, EmployeeID; | 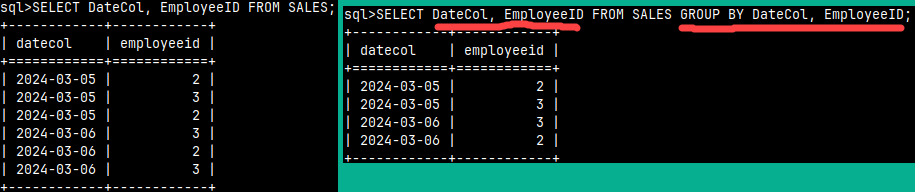 |
GROUP BY will remove rows for non-aggregated columns by removing duplicates. For columns like Quantity and Value, we can consolidate rows by aggregating the values.SELECT DateCol |  |
| If one of the columns we are grouping on is an expression, then we have to use alias for that expression in the GROUP BY. SELECT DateCol |  |
Using VALUES Clause
We can create a SELECT statement that will return our hard-coded values.
SELECT * FROM ( VALUES (0,'cero'), (1,'uno'), (2,'dos'), (3,'tres') ); |  |
We can also give such a table an alias.SELECT * FROM ( VALUES (0,'cero'), (1, 'uno' ) ) AS TableName(Number, Word);This alias will come in handy in some more complex statements. |  |